
As DoorDash began migrating to a microservice architecture in 2019, we found it critical to extract APIs for DoorDash Drive, our white label logistics platform, from our previous monolithic codebase. Extracting these APIs improves our ability to monitor them and ensure Drive operates reliably.
DoorDash Drive provides last mile, on-demand logistics solutions to business owners, and Drive Portal is the platform where deliveries are requested and tracked. All the APIs used by the Portal were living under a monolith shared among dozens of services. We built this monolithic codebase in our formative years, but as we grew, we decided a microservice architecture would better suit our needs.
We divided the API extraction process into three phases. The most important, separation, required us to understand each API’s business logic and map out its endpoints. During the testing phase we ran various payloads to make sure our freshly extracted APIs worked as expected. And finally, we organized the APIs into batches for the shipping phase and monitored them closely to ensure performance in the production environment.
DoorDash’s move to a microservice architecture had to be accomplished so as not to disrupt services running on our platform, requiring strategic thought all around. Extracting the Portal APIs for DoorDash Drive was one of many efforts taken on by our engineering organization.
Mobilizing for extraction
In April 2020 DoorDash mobilized a large part of our engineering organization to migrate from our monolithic codebase to a microservices architecture. We planned this migration to improve the quality, reliability, and developer velocity on our platform. Amongst the many projects within this migration was an effort to extract APIs powering DoorDash Drive from the monolith and move them over to the new microservice architecture.
For example, one of the Drive APIs gets all the stores accessible by the user. Since the authentication between users and stores is slightly different between DoorDash’s consumer marketplace platform and Drive, it becomes very complicated to modify the existing model to support Drive’s special use cases.
As the APIs are provided to all services, any code change would impact the Drive Portal’s behavior without the engineers necessarily knowing it. Additionally, any outage in the monolith would hugely impact the Drive Service if we are fully dependent on the monolith.
As a first step for the Drive Portal API extraction part of this project, we implemented controllers for each endpoint in our Drive Backend For Frontend (Drive BFF) to accept the same requests and payloads from the frontend, and redirect them to the monolith.
The key challenge of the extraction wasn’t the extraction itself. Instead, it was learning and understanding each API’s business logic, where it was implemented in the monolith, and its specific Drive use case. For example, one API allows Merchant users to search their history of deliveries by date range and keywords, returning delivery details including delivery ID, Dasher name, and the actual delivery time. Upon further investigation of this API we found that 42 endpoints similar to this one were used on the Drive Portal. Although this quantity might seem daunting, the number of APIs wouldn’t be a concern if we knew how to break them down into smaller pieces.
Three steps to ensuring a successful extraction
Although the entire migration involves big changes to DoorDash’s platform, our active users should feel no disruption when using our services during this process. Achieving this goal required a cautious and detail-oriented approach for each and every step in the extraction process. Also, getting parity between these architectures didn’t mean copying and pasting code, but actually improving efficiency at the same time.
To maintain a stable experience for our users during the migration, we came up with three steps to make each part of the extraction small enough so that no details would be missed or overlooked.
- Separation: Understanding the API’s business logic and replicating it in the new environment
- Testing: Ensuring that each API acts like we expect on our staging server
- Shipping: Putting the API into production and monitoring it for anomalies
Using this process makes our extraction efforts manageable and safe, preserving the reliability of our platform.
Separation: Categorization by function
The most important step among all three is separation. This step not only helped us comprehend the scope of the whole project, but also made sure that we did not miss any endpoints when we discussed the details of each service.
We were able to break down all the 42 APIs in the Drive Portal into five Service Groups, including Catering Service, Dasher Service, Delivery Service, Merchant Service, and Notification Service.

Within each group, the APIs achieve similar functionalities. The existing code is located closely together in the monolith, and so can be placed under the same controller after the extraction.
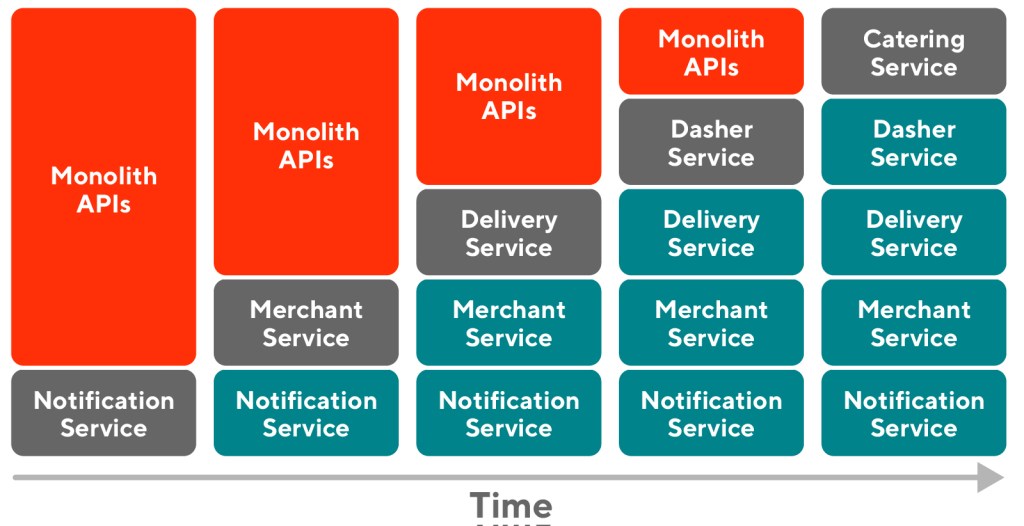
The Separation stage also helped us clear out the timeline of the entire extraction process. We then prioritized the APIs with fewer dependencies and which were easiest to implement, leaving the rest for later as we got more familiar with the procedure.
Testing: Verifying behavior
There are many details and variations in the API implementation that can be easily missed. For example, user authentication, endpoint parameter validation, and serialization are all essential parts of the extraction. To mitigate all potential errors or mistakes, we created a suite of test cases for every group of endpoints to make sure the behavior was identical to the existing APIs. All the test cases were first written and tested in our staging environment, and then reused in production environments.
Because we are working remotely, we hosted a Testing Party over Zoom where engineers who had worked on Drive Portal tested the functionality of the endpoints they were familiar with. We checked off endpoints with no issues and wrote down action items for endpoints that didn’t behave as expected.
Shipping: Tracking and batching
Even if we fully tested all APIs locally and on a staging server, there might still be some uncaught errors. We were very cautious when rolling out such a big change, so we planned for the worst.
There were two important components of the Shipping step, Tracking and Batching. The former monitored for any issues that developed in production, and the latter let us manage the API deployment to ensure reliability.
Tracking HTTP response
We would never ship a feature without a mechanism to monitor its performance. Not surprisingly, monitoring is another benefit we gained from extracting our APIs. We created an informative dashboard showing all the Portal APIs statuses in detail, including queries per second (QPS), latency, and response status. We added multiple alerts with these metrics so engineers can react quickly if problems arise.
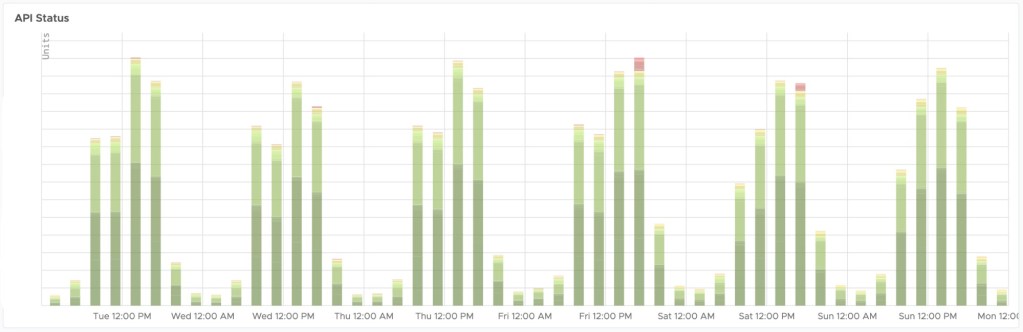
Batching APIs
We batched APIs into separate deployments according to their groups. For each batch, we built a new web release and only exposed it to a certain percentage of our users. We closely monitored all the metrics on the dashboard and gradually rolled it out to 100% of users.
Batching APIs dramatically reduced the risk of each deployment. Though the process took longer, it was much more manageable and actionable if any error occured.
Results
Following this three step extraction process, we caught 100% of errors before rolling out to production, and were able to redirect all requests through the BFF. Any outages experienced on the monolithic codebase we were moving away from caused only limited degradation or no impact on the Drive Portal. The migration hasn't been fully completed yet, but we are confident that following this process will effectively lead us to completion in the near future.
Migrating from a monolithic codebase to a microservice architecture is not uncommon, especially among startups that find success with increasingly large user bases. As in DoorDash’s case, these migrations often need to occur on production platforms, potentially risking disruption to business services. The example of API extraction described in this article, although only one part of a larger project, indicates how careful planning and a well-documented process can lead to error-free deployments.
Acknowledgement
Special thanks to Alok Rao, William Ma, Dolly Ye, and everyone on DoorDash’s Drive team for learning together with me and their support during this project.
Header photo by Simon Goetz on Unsplash.











