
It would be almost impossible to build a scalable backend without a scalable datastore. DoorDash’s expansion from food delivery into new verticals like convenience and grocery introduced a number of new business challenges that would need to be supported by our technical stack. This business expansion not only increased the number of integrated merchants dramatically but also exponentially increased the number of menu items, as stores have much larger and more complicated inventories than typical restaurants. This increased volume of items created high latency and high failure rate in the fulfillment backend mainly caused by database scalability problems.
To address these scalability issues we did a major overhaul of the legacy architecture and adopted CockroachDB as its new storage engine. Our team’s goal was to utilize CockroachDB to build a scalable and reliable backend service that could fully support our business. CockroachDB is a scalable, consistently-replicated, transactional datastore, and it’s designed to run on the cloud with high fault tolerance.
This article will take a deep dive into the steps we took to migrate over to CockroachDB and how we ensured that migration was smooth and successful. Specifically we will discuss:
- The issues and problems associated with the legacy store_items implementation
- Why we chose CockroachDB
- How we migrated to CockroachDB successfully
- Our results and learnings
The challenges with the legacy store_items implementation
store_items is a materialized view that contains catalog, inventory, and pricing data for all the convenience and grocery items. It’s hosted in the PostgreSQL and used to serve item metadata to the Dasher, our name for delivery drivers, during order fulfillment.
Our legacy store_items table had successfully gotten the new vertical business started, but needed to be a lot more scalable if we wanted to support 10x volumes. There were three main concerns that we needed to address:
- Performance concerns
- Maintenance concerns
- Anti-patterns that needed to be fixed
Let’s dive into each one of these:
Performance concerns:
As our use cases evolved, our OLTP database usage went up to 500GB very quickly, which was problematic as our internal recommended single PostgreSQL table size is under 500GB. Tables over the limit can become unreliable and we started observing performance issues. In particular, we noticed slower SQL inserts because all the updates went through a single writer instance. Especially during peak hours, we observed our latency metrics double in overall services when we did large amounts of non-batching non-partition upserts, which increased the database CPU usage to more than 80%.
Maintenance concerns:
Legacy single writer/multiple read replica kind of database cluster adopted by us, its primary writer instance is located in a single availability zone of a region, there is a risk of higher customer-perceived latencies as we continue to expand to different geo-regions and countries, because of the distance between the servers and users. Having one zone is also a single point of failure with one AWS region taking down the entire DoorDash new verticals business.
Anti-patterns that needed to be fixed
An anti-pattern in software engineering is a common response to a recurring problem that is usually ineffective and risks being highly counterproductive. Detecting and addressing anti-patterns in the software plays a very critical role in system reliability and scalability. We had discovered several anti-patterns in the legacy store_items workflow:
- direct database access from the business layer without a data-service layer
- foreign key joins and excessive secondary indices overloading the database
- business logic within the database query itself, and
- The JDBC interfaces are thread blocking.
- This means if you use a JDBC call, it will BLOCK the entire thread you are on (not just the coroutine–the entire underlying thread). This can have a disastrous effect on the number of requests you are able to handle simultaneously
Each of these was taken care of along with the migration, that we will explain in more detail below.
For the first two concerns listed above, we actively explored solutions including:
- Split store_items table to multiple tables so that each table will have less than 500 GB
- Use s3 blob storage to store the actual data while keeping the s3 URLs in the DB table
- Adopt CockroachDB to solve the scalability problem once for all while keeping a structured, tabular data model based on SQL
Eventually the team decided to use CockroachDB to solve the scalability problem, which will be explained in detail in the next section.
Why we choose CockroachDB to replace PostgreSQL
CockroachDB’s distributed nature makes it perfect for our migration given its high reliability, additional features support, and a modern event-driven architecture that is more performant.
We decided on CockroachDB because it is based on a shared-nothing architecture, in which each node in the system is independent and has its own local storage. This distributed aspect of the technology can make CockroachDB more resilient to failures and more scalable, as nodes can be added or removed without disrupting the system. CockroachDB also supports distributed transactions. Cockroach DB’s changefeeds enables modern event-driven architecture. Thus CockroachDB is naturally a better choice for applications requiring high resilience, scalability, and support for distributed data and transactions.
How we migrated to CockroachDB:
We migrated from the legacy database to CockroachDB in four major milestones.
- migrating all legacy data-retrieval flows to a new DB facade layer,
- making schema changes and backfilling the data store,
- executing shadow reads and data comparisons,
- doing database cutover and cleanup.
We will talk about each of these milestones in the following sections.
Building the database facade layer:
The first thing we did as part of the migration was to cut down all the direct database access through a service facade layer named Retail Fulfillment Data Service (RFDS). We identified three to four predominant query patterns and built gRPC APIs in a new purpose-built service to serve these key query patterns.
Running the database behind a service facade had multiple advantages:
- Callers of RFDS don’t need to know the low-level database schema as long as we were able to keep the service API intact.
- Adding any caching logic will be easier for better performance.
- Data migration (which is the primary reason in our case) is easier because of CockroachDB’s distributed nature.
- Leveraging DoorDash’s standardized gRPC service offerings to improve the downstream query reliability and observability, e.g. health check, rate limiting, load shedding, metrics, logging, error handling, dashboards, etc.
Since different queries/clients requested different columns, we used protobuf fieldmask to allow clients to specify the attributes they were interested in. This feature helps to keep the API lean and avoid bugs and unnecessary data transfer. As part of the first phase of migration, we worked with our customers to migrate to Retail Fulfillment Data Service (RFDS) as we continue to work the rest of the migration process.
Subscribe for weekly updates
Key low-level design choices:
The devil is in the details. Here we list the key low-level design choices we made, which helped us:
- Better integrate and leverage CockroachDB
- Schema changes
- Column families
- JSONB columns
- Eliminate legacy implementation anti-patterns
- Deprecate joins
- Reduce indices usage
- Multi-row data manipulation
We will go through all of these different attributes below.
Schema changes: The conventional wisdom suggests minimizing the changes we make as part of complex migrations. However, we made a conscious choice to modify the schema so that we can better leverage the underlying database strengths. This choice also helped us to skip one or two steps to reach our end state faster. We think migrating clients to the new Retail Fulfillment Data Service(RFDS), internal facade service, and isolating them from the underlying schema is the best reason why we would take such a huge risk in the migration.
Adopt column families: When a CockroachDB table is created, all columns are stored as a single column family. This default approach ensures efficient key-value storage and performance in most cases. However, when frequently updated columns are grouped with seldom updated columns, the seldom updated columns are nonetheless rewritten on every update. Especially when the seldom updated columns are large, it's more performant to split them into a distinct family. We looked into legacy query patterns for store_items and found that there are certain columns in store_items such as price, availability, or flag that change often compared to the rest of the columns such as bar-code, image link, etc. After isolating frequently updated columns into separate column families, we can update only non-static columns instead of a full row replacement. This improved the SQL update performance by over 5X.
Leverage JSONB columns: While looking into CockroachDB feature list, we found that CockroachDB’s JSONB columns can be very helpful for several reasons.
- Supporting top-level partial update
- SerDes Protobuf schema <> JSON through JDBI codec to make the json schema versioned, backward compatible, and strongly typed
- Adding/removing a field from JSONB column does not require a database table migration
- Indexing a field in a JSONB column is supported
- Computed column can be used to persist a field from JSONB to a separated column if needed
- Check constraint can be used for json field validation
So we decided to group columns from legacy PostgreSQL store_items table into different CockroachDB JSONB columns based on their corresponding column family
Deprecate SQL joins: One of the conscious choices we made as part of this migration is to avoid SQL joins so that we can improve the overall performance of the system. SQL joins over large tables are some of the most expensive operations which are generally not recommended in an online service. Additionally, it coupled the business logic into the SQL query which is not a preferred coding convention. We replaced the SQL join with downstream service calls or simple SQL select queries so that the result dataset can be joined in-memory through the code.
Reduced indices usage: With the migration, we drastically reduced the number of secondary indices from eight (in the original table) to two secondary indices (in the new table). Using the built-in unique key made up of composite columns in the data itself allowed us to forgo the artificial auto-increment key and random generated UUID as unique ids and save on secondary indices. Auditing the query patterns after we segregated the joins and converting them to a simple Get API allowed us to keep the number of secondary indices to two.
Multi-row data manipulation: For INSERT, UPSERT, and DELETE statements, a single multi-row statement is faster than multiple single-row statements. So we use multi-row statements for DML queries instead of multiple single-row statements, which dramatically improves the write performance and throughput.
Making the final switch to CockroachDB
Once all our clients migrated to the RFDS for their read and write use cases, we started populating the tables in the CockroachDB instance as part of every real-time write operation to store_items. In parallel, we also started doing bulk writes, making our merchant inventory injection jobs write to both the legacy database instance and CockroachDB. We first made CockroachDB as a shadow with the legacy database as primary. The shadow is populated through async calls and this is a conscious choice we made to avoid keeping CockroachDB as part of the critical flow.
To test the equivalency of both tables, in the read path we read from both the legacy database instance and the CockroachDB instance from the new table, as depicted in figure 1. We compared data on both the existence of the same store items in both tables and the equivalence of attributes in case both store items exist. The Mapdifference API proved to be particularly useful to detect skew in the tables and helped us catch any missing update paths.
Over time, we compared the output and fixed any bugs that caused differences. Once we gained confidence that our reads were consistent across both the data stores, we flipped the primary and shadow roles making CockroachDB the primary database and legacy database the shadow so that the shadow was the fallback when the primary was unavailable. We repeated a similar analysis and this time included key business metrics as well for validation.
Once we accounted for the observed differences (old/stale rows, default/missing values, etc) and fixed the missing updates we were ready to cutover the traffic to the new table. We used a feature flag to dynamically route queries to the legacy table or the new service. We gradually rolled out the feature flag to divert the traffic to the new service completely and scaled out the new service and CockroachDB cluster as needed.

Results
Besides eliminating the scaling bottleneck, we also improved overall query performance considerably with the migration and because of the choices that we made along the way.
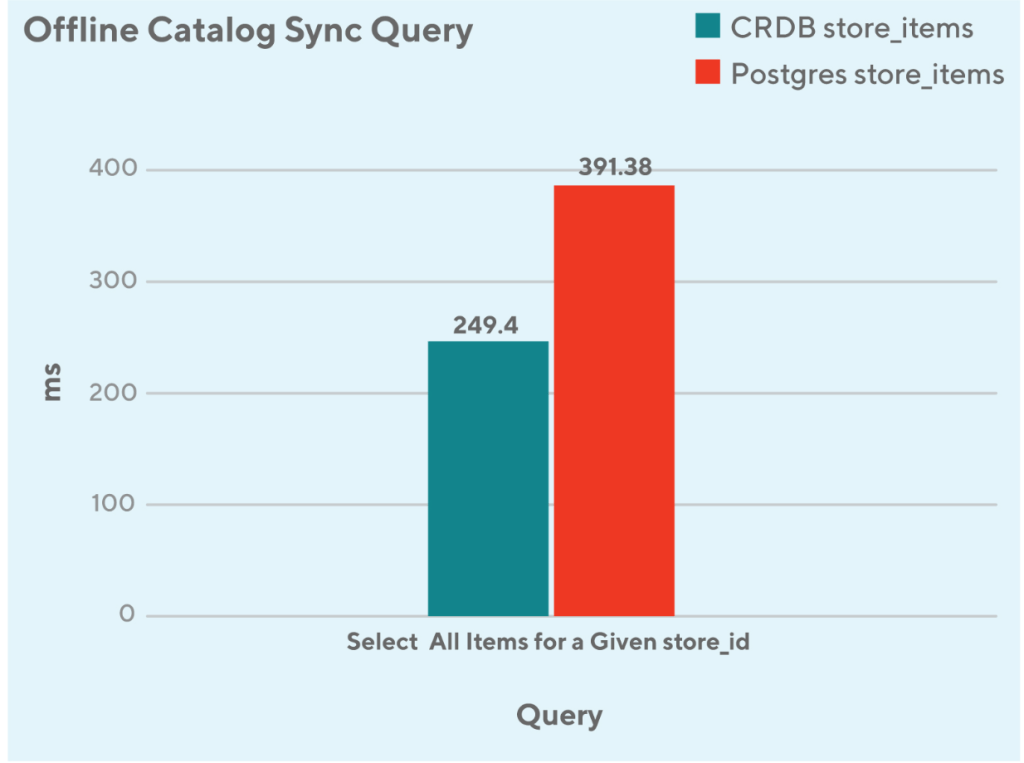
The first example here is as depicted in figure 2: select query performance based on store_id dropped by ~38%. The reason for that is that in CockroachDB, store_id is the first column in the composite primary key; however, it’s just an ordinary secondary index in the PostgreSQL table.
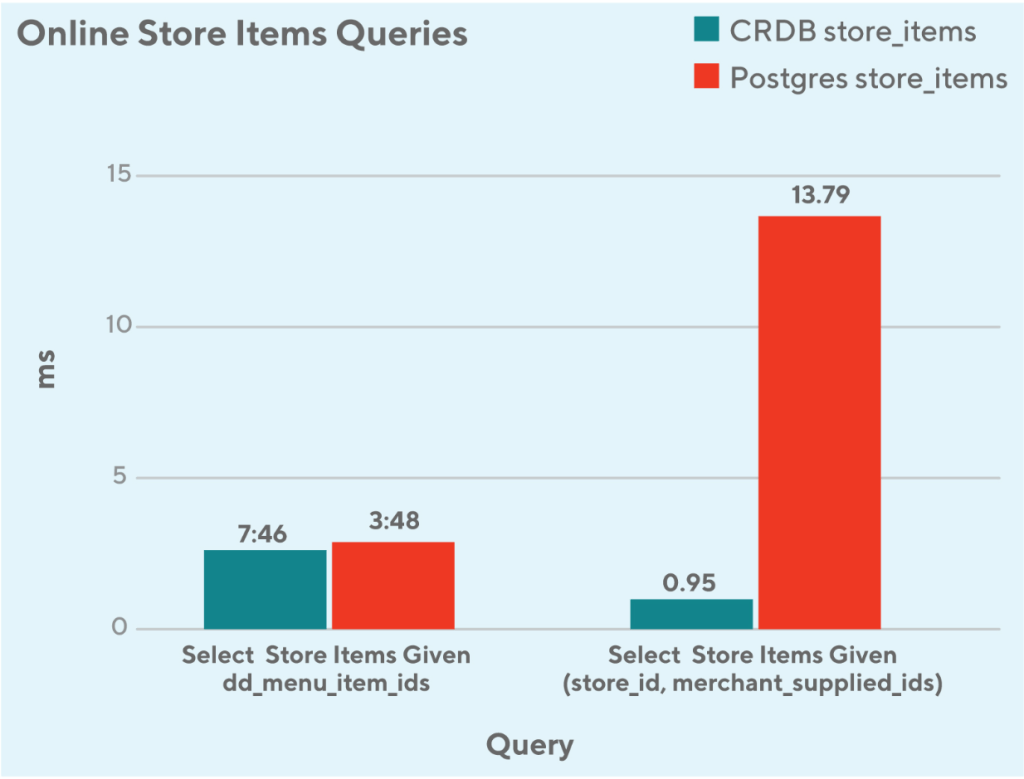
For the rest of online queries as depicted in figure 3, there are two major patterns:
- Query against dd_menu_item_ids
- It’s designed to be a secondary index for both data stores, the performance is on par
- Query against store_id + merchant_supplied_id
- It’s the composite key in the CockroachDB table however it’s just a composite secondary index in the PostgreSQL table, the query performance is significantly improved (10x faster) in the CockroachDB compared to the PostgreSQL
Conclusion
A scalable backend needs to be backed by a scalable datastore. Any technology has its own pros and cons, and there is no one-size-fits-all solution. What this article presented here is one of the ways to deal with OLTP datastore scalability problem, in the meanwhile we also shared the tech debt in the legacy design, new features adoption in the CockroachDB and how to plan a seamless bug-free migration. Here is the summary:
- DoorDash has a recommended size limit 500 GB for a single PostgreSQL table
- CockroachDB's shared-nothing architecture makes it a perfect fit for high resilience, scalability, and support for distributed data and transactions.
- Eliminate the tech debt like foreign key, redundant secondary indices, SQL join statements, etc, in the new design
- First dual write, then shadow read, and eventually feature-flag-based cutover for a seamless bug-free migration
Those who find themselves in a similar situation of encountering OLTP database scalability bottleneck can take the following steps:
- Make your SQL query as simple as possible, move data join from SQL level to the service code, or build a materialized view to store the precomputed join
- Use the built-in unique key made up of composite columns in the data itself. This allowed us to forgo the artificial auto-increment key and random generated UUID as unique IDs and save on secondary indices
- Use multi-row statements for DML queries to replace multiple single-row statements
- Create a facade layer to unify the data access interfaces and isolate the application from the storage engine and facilitate the migration
- Understand that CockroachDB is naturally a better choice for applications requiring high resilience, scalability, and support for distributed data and transactions.
This migration allowed us to resolve a lot of legacy tech debt and performance concerns. We are now also in a stage where we can handle 10X load as we continue to scale our new verticals business.





 WayneCunningham
WayneCunningham

 QixuanWang
QixuanWang





