



While building a feature store to handle the massive growth of our machine-learning ("ML") platform, we learned that using a mix of different databases can yield significant gains in efficiency and operational simplicity. We saw that using Redis for our online machine-learning storage was not efficient from a maintenance and cost perspective. For context, from 2021 to 2022, our team saw the number of ML features being created by ML practitioners at DoorDash increase by more than 10x.
To find a more efficient way to accommodate the growth, we decided to research using a different database to supplement Redis as a backend for our online feature store. Ultimately, we settled on using CockroachDB as a feature store. After iterating using the new platform, we were able to reduce our cloud-spend per value-stored on average by 75% with a minimal increase in latency. In the rest of this post, we’ll be going over all of our learnings on operating a fleet of Redis clusters at scale and what we learned after using CockroachDB to augment our online serving platform.
Maintenance overheads of large-scale Redis clusters
If you read the prior blog post on our feature store (a must-read), you might be asking, ‘Why add another database?’ Redis looked like the runaway favorite candidate by every conceivable metric. However, once we introduced Fabricator, our internal library for feature engineering, we saw the number of machine learning use cases skyrocket, and as a consequence, the number of features being created and served online also increased dramatically. The increased number of features meant that at a certain point, our team was upscaling a Redis cluster once a week. We also needed to institute capacity checks to prevent feature uploads from using up to 100% of the memory on the cluster.
We quickly learned that upscaling our large Redis clusters (>100 nodes) was an extremely time-consuming process that was prone to errors and not scalable. Upscaling using the native AWS ElastiCache consumed extra CPU, and that caused latencies to increase, resulting in an indeterminate amount of time required to complete a run. To make sure our jobs ran in a timely manner, we had to create our own approach to scaling Redis in a way that was acceptable to our business objectives. After a few different iterations, we eventually settled on a simple process with almost no downtime.
Our process for upscaling large Redis clusters with zero downtime
When our Redis clusters get overloaded due to the number of new features that are created, we need to increase the resources and underlying infrastructure. Our process for upscaling is similar to a blue-green deployment process:
- Spin up a Redis cluster with the desired number of nodes from the most recent daily backup
- Replay all of the writes from the last day on the new cluster
- Switch over traffic to the new cluster
- Delete the old cluster
On average upscaling our Redis clusters would end up being a 2-3 day process since the different steps would need to be coordinated with all the teams in charge of provisioning cloud infrastructure and other teams relying on the service for support. Switchovers would always be executed in off-peak hours to minimize service disruptions. Sometimes restoring backups would fail due to a lack of AWS instance types so we would need to contact AWS support and try again.
Why we added CockroachDB to our ecosystem
Even though we saw in prior benchmarks that it had higher latencies for a variety of read/write operations compared to Redis, we decided that CockroachDB would serve as a good alternative for a variety of use cases that do not require ultra-low latency and high throughput. In addition, CockroachDB has a variety of attributes that make it very desirable from an operational standpoint including:
- Database version upgrades and scaling operations result in 0 downtime
- CockroachDB supports auto-scaling behavior based on load both at a cluster and a range level
- The data being stored in sequential ranges makes for desirable properties that can improve performance down the line
- Disk-based storage makes the cost of storing high cardinality features much cheaper
What makes CockroachDB different
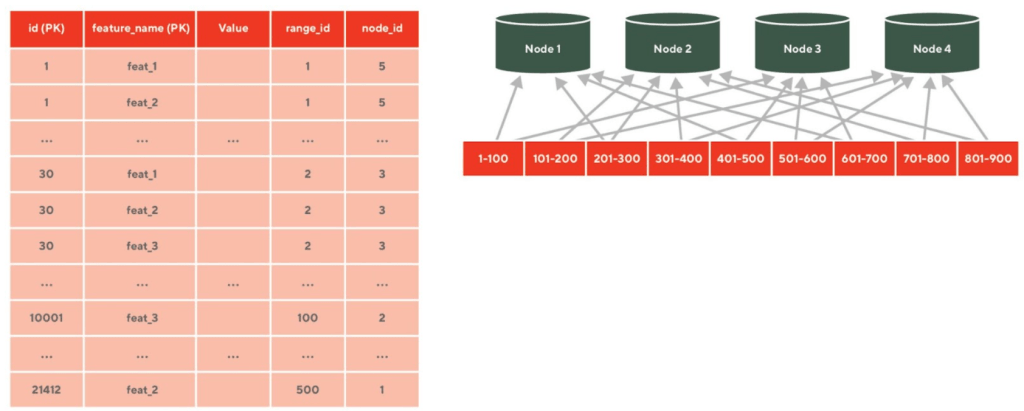
What differentiates CockroachDB from other databases, besides its performance, is its unique storage architecture. At a high level, CockroachDB is a Postgres-compatible SQL layer that is capable of operating across multiple availability zones. Underneath the SQL layer is a strongly-consistent distributed key-value store. Like Cassandra, data is stored using an LSM. But the key difference between Cassandra and CockroachDB is that instead of using a ring hash to distribute the keys across nodes, CockroachDB stores keys in ordered chunks called "ranges," where a range is an interval of primary keys between two values (as depicted in Figure 1). Ranges will grow up to a given size and once the range exceeds that size, it will automatically split, allowing the new decomposed ranges to be distributed across different nodes. Ranges can also split automatically when the number of queries hitting the range exceeds a defined threshold, making it resilient to spikes in traffic and skewed read patterns.
Initial design optimizations and challenges
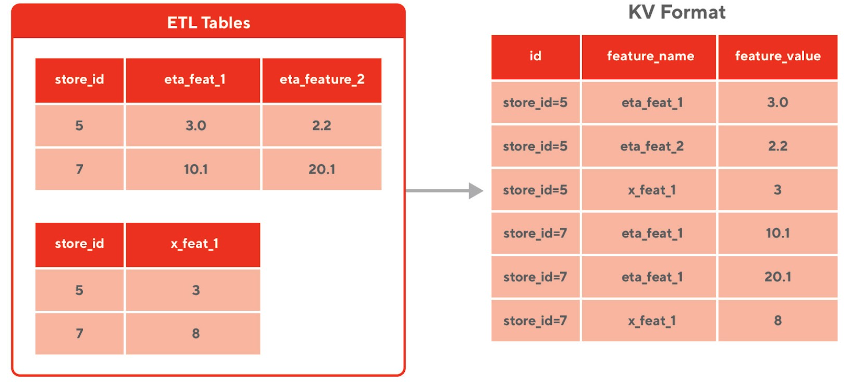
Our initial design for the feature store sought to use the entity key and feature name as the primary key (shown in Figure 2). This primary key matched the current pattern of our upload service, where we would queue up features from a table and upload them into Redis via entity and feature value.
Part of the scope of our initial design was to figure out what would be the read/write behavior. Along the way, we learned a lot of optimizations to get the highest possible upload throughput.
Write batch sizes need to be small
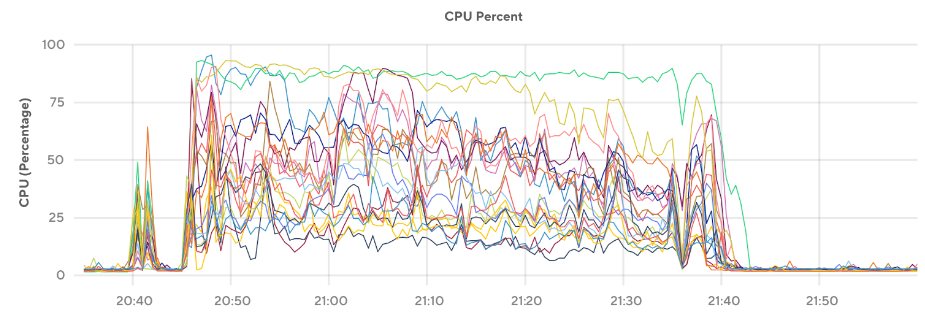
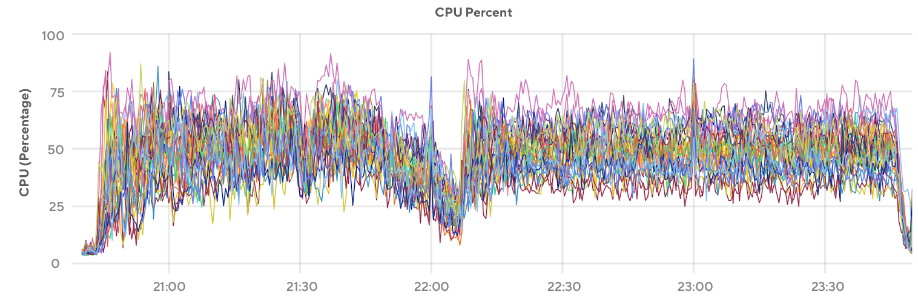
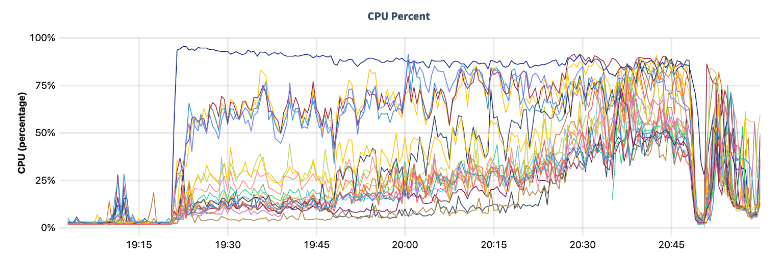
When batch sizes are large (e.g., >1000 values per INSERT query), the entire cluster grinds to a halt and throughput drops since queries are limited by the slowest node executing any part of the query (see Figure 3). Performance also becomes impacted from contention due to the serialized isolation level. So this can result in skewed CPU usage that limits the performance of the cluster. When lowering the number of values per query and increasing the number of threads, a similar throughput can be achieved, but with a much better-balanced CPU load (shown in Figure 4).
Tables need to be prepared for high write throughput after being created
Since every table starts with a single range, it also means that all the writes can only be done on a single node to start with, and as a result throughput to be limited to the performance of a single node until the workload starts to be decomposed and distributed across the cluster (Figure 5). It is possible to mitigate this warm-up behavior by pre-splitting ranges on the table with a command or throttling write throughput until the table creates enough ranges to be distributed across the cluster.
Other design considerations
Besides those two main considerations we also did the following:
- Inserting the entire row, instead of a subset of values eliminates the `read` from the query plan (called a fast path insert) and decreases CPU usage by ~30%
- By chunking incoming feature value requests into many smaller queries with aggressive timeouts, we’re able to significantly reduce read request times and improve the overall reliability of the service.
- By sorting the values within each partition being uploaded, we are also able to decrease the number of nodes a given query touches, reducing the overall CPU consumption
Subscribe for weekly updates
Using CockroachDB as a feature store in production
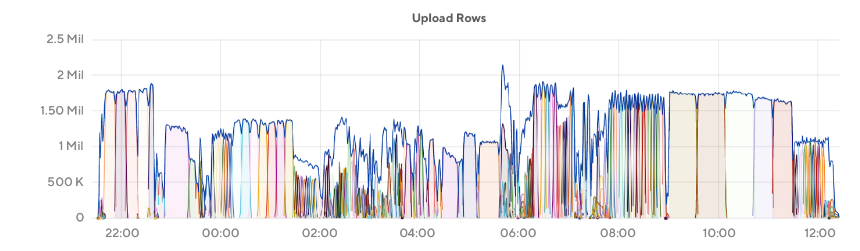
After doing some explorations on read and write sizes, we decided to move CockroachDB into production for a small number of use cases while also double-writing the majority of our features to facilitate a quick migration for existing use cases. We ended up observing that write throughput was much lower than we expected and extremely inconsistent over the lifetime of our upload workload. Using 63 m6i.8xlarge instances (AWS EC2 Instance Types), we were able to insert approximately 2 million rows per second into the database at peak (see Figure 6), while utilizing an average of ~30% of the CPU of the cluster. However, at times we would see CPU utilization spike to 50-70% and the number of values we were inserting into the database per second would drop by 50%+ to less than 1 million rows per second.
After working with some engineers from Cockroach Labs, we learned that the number of ranges that are being accessed at a given time will increase the CPU usage on writes, causing each query running to execute much slower than before (as shown in Figure 7). The more writes there are, the more the cache is occupied by data from writes instead of the data being requested for reads, causing the read requests to have a higher latency.
At this point using some back-of-the-envelope calculations, we were storing feature values at roughly 30% of the cost of Redis. As the number of values we were writing was increasing, performance was getting worse, since the number of ranges a given entity space would occupy was increasing, meaning that our efficiency and gains compared to using Redis would continue to go down. A 30% decrease in costs wasn’t quite the win we were hoping for, so we tried to look for some ways we could decrease the number of writes and save some CPU.

Condensing our writes using JSON Maps
Our prior tests showed significant improvements in performance when using a NoSQL approach, where values for an entity are stored in a JSON map, but had some concerns with this approach since the documentation on CockroachDB indicates that performance may start to degrade once the JSON map is >1MB in size.
With some brainstorming we were able to come up with ways to constrain the size of our JSON maps by using a primary key based on the ETL job it was generated by (shown in Figure 8). This resulted in near-linear gains in read/write performance with increased feature values in a single row (shown in Figures 9 and 10). This also ends up being much more efficient than merging to an existing JSON map since a merge into a JSON map in SQL requires an extra read operation in the query plan.

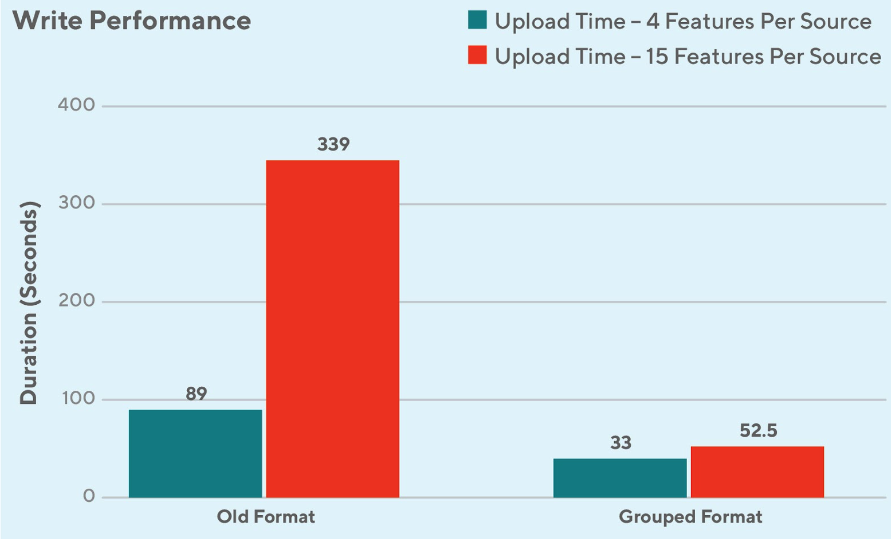
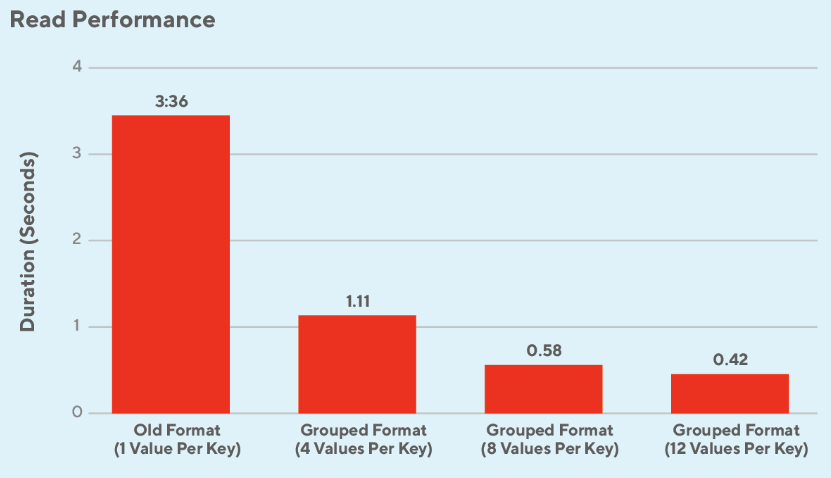
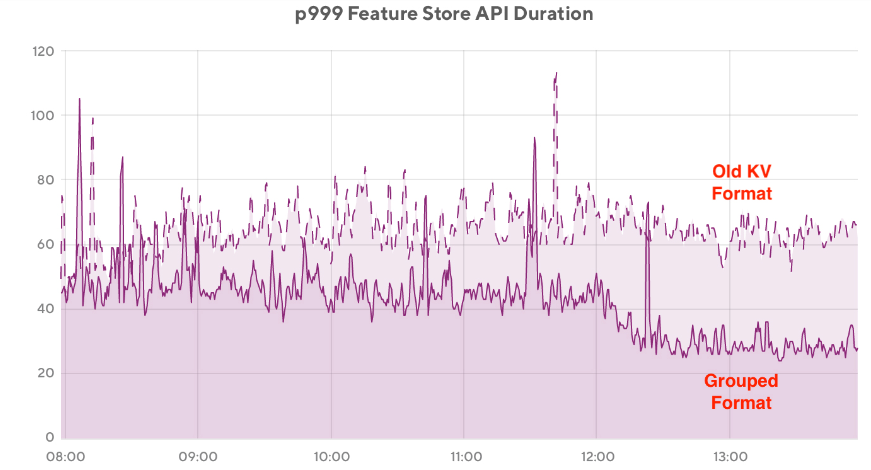
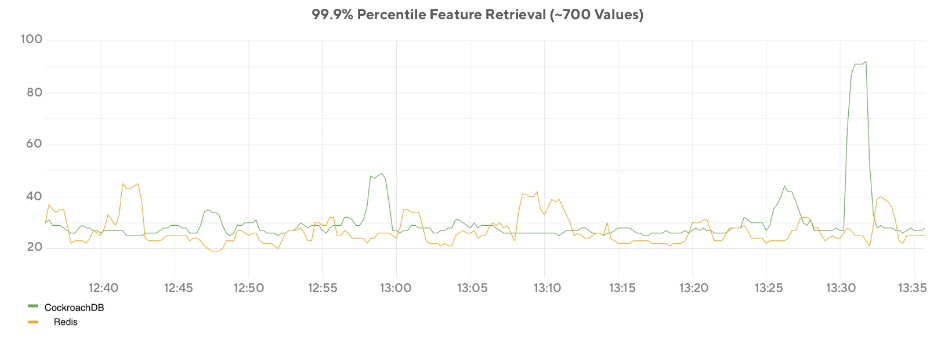
This format resulted in efficiency increase up to 300% higher compared to the original format on average for writes (see Figure 11) and saw the read latency for existing use cases drop by 50% (see Figure 12). The increases in efficiency were due to decreases in the number of ranges a feature occupies and decreases in the number of write operations required. The resulting improvement in read performance also showed that in some cases CockroachDB can reach similar performance levels to that of Redis on a similar workload (see Figure 13).

Final thoughts
Even though we’ve seen these savings by using CockroachDB as a feature store, there are still many use cases where using Redis makes sense. For services with an extremely high-volume of reads relative to the number of values, or cases where the total size of the data being stored is low, Redis is definitely still a great choice. As a matter of fact, we are still using Redis for over 50% of our features today. In general though, we think there is still a lot of performance left to squeeze out of our existing implementations and we’re just scratching the surface of what we’re capable of doing with CockroachDB and will continue to iterate and share our learnings.
Hopefully readers can utilize the learnings we shared in this post to create an optimal solution of their own that is highly tailored to the needs of their machine-learning platform.
Acknowledgments
This was a huge, 7-month effort across multiple teams. Special thanks to everyone who was involved in the effort.
Dhaval Shah, Austin Smith, Steve Guo, Arbaz Khan, Songze Li, Kunal Shah
And an extra special thanks to the Storage Team and Cockroach Labs folks for answering 5 million questions on performance tuning!
Sean Chittenden, Mike Czabator, Glenn Fawcett, Bryan Kwon











