


Scaling backend infrastructure to handle hyper-growth is one of the many exciting challenges of working at DoorDash. In mid 2019, we faced significant scaling challenges and frequent outages involving Celery and RabbitMQ, two technologies powering the system that handles the asynchronous work enabling critical functionalities of our platform, including order checkout and Dasher assignments.
We quickly solved this problem with a simple, Apache Kafka-based asynchronous task processing system that stopped our outages while we continued to iterate on a robust solution. Our initial version implemented the smallest set of features needed to accommodate a large portion of existing Celery tasks. Once in production, we continued to add support for more Celery features while addressing novel problems that arose when using Kafka.
The problems we faced using Celery and RabbitMQ
RabbitMQ and Celery were mission critical pieces of our infrastructure that powered over 900 different asynchronous tasks at DoorDash, including order checkout, merchant order transmission, and Dasher location processing. The problem DoorDash faced was that RabbitMQ was frequently going down due to excessive load. If task processing went down, DoorDash effectively went down and orders could not be completed, resulting in revenue loss for our merchants and Dashers, and a poor experience for our consumers. We faced issues on the following fronts:
- Availability: Outages caused by demand reduced availability.
- Scalability: RabbitMQ could not scale with the growth of our business.
- Observability: RabbitMQ offered limited metrics and Celery workers were opaque.
- Operational efficiency: Restarting these components was a time-consuming, manual process.
Why our asynchronous task processing system wasn’t highly available
This biggest problem we faced were outages, and they often came when demand was at its peak. RabbitMQ would go down due to load, excessive connection churn, and other reasons. Orders would be halted, and we’d have to restart our system or sometimes even bring up an entirely new broker and manually failover in order to recover from the outage.
On diving deeper into the availability issues, we found the following sub-issues:
- Celery allows users to schedule tasks in the future with a countdown or ETA. Our heavy use of these countdowns resulted in noticeable load increases on the broker. Some of our outages were directly related to an increase in tasks with countdowns. We ultimately decided to restrict the use of countdowns in favor of another system we had in place for scheduling work in the future.
- Sudden bursts of traffic would leave RabbitMQ in a degraded state where task consumption was significantly lower than expected. In our experience, this could only be resolved with a RabbitMQ bounce. RabbitMQ has a concept of Flow Control where it will reduce the speed of connections which are publishing too quickly so that queues can keep up. Flow Control was often, but not always, involved in these availability degradations. When Flow Control kicks in, the publishers effectively see it as network latency. Network latency reduces our response times; if latency increases during peak traffic, significant slowdowns can result that cascade as requests pile up upstream.
- Our python uWSGI web workers had a feature called harakiri that was enabled to kill any processes that exceeded a timeout. During outages or slowdowns, harakiri resulted in a connection churn to the RabbitMQ brokers as processes were repeatedly killed and restarted. With thousands of web workers running at any given time, any slowness that triggered harakiri would in turn contribute even more to slowness by adding extra load to RabbitMQ.
- In production we experienced several cases where task processing in the Celery consumers stopped, even in the absence of significant load. Our investigation efforts did not yield evidence of any resource constraints that would’ve halted processing, and the workers resumed processing once they were bounced. This problem was never root caused, though we suspect an issue in the Celery workers themselves and not RabbitMQ.
Overall, all of these availability issues were unacceptable for us as high reliability is one of our highest priorities. Since these outages were costing us a lot in terms of missed orders and credibility we needed a solution that would address these problems as soon as possible.
Why our legacy solution did not scale
The next biggest problem was scale. DoorDash is growing fast and we were quickly reaching the limits of our existing solution. We needed to find something that would keep up with our continued growth since our legacy solution had the following problems:
Hitting the vertical scaling limit
We were using the largest available single-node RabbitMQ solution that was available to us. There was no path to scale vertically any further and we were already starting to push that node to its limits.
The High Availability mode limited our capacity
Due to replication, the primary-secondary High Availability (HA) mode reduced throughput compared to the single node option, leaving us with even less headroom than just the single node solution. We could not afford to trade throughput for availability.
Secondly, the primary-secondary HA mode did not, in practice, reduce the severity of our outages. Failovers took more than 20 minutes to complete and would often get stuck requiring manual intervention. Messages were often lost in the process as well.
We were quickly running out of headroom as DoorDash continued to grow and push our task processing to its limits. We needed a solution that could scale horizontally as our processing needs grew.
How Celery and RabbitMQ offered limited observability
Knowing what’s going on in any system is fundamental to ensuring its availability, scalability, and operational integrity.
As we navigated the issues outlined above, we noticed that :
- We were limited to a small set of RabbitMQ metrics available to us.
- We had limited visibility into the Celery workers themselves.
We needed to be able to see real-time metrics of every aspect of our system which meant the observability limitations needed to be addressed as well.
The operational efficiency challenges
We also faced several issues with operating RabbitMQ:
- We often had to failover our RabbitMQ node to a new one to resolve the persistent degradation we observed. This operation was manual and time consuming for the engineers involved and often had to be done late at night, outside of peak times.
- There were no in-house Celery or RabbitMQ experts at DoorDash who we could lean on to help devise a scaling strategy for this technology.
Engineering time spent operating and maintaining RabbitMQ was not sustainable. We needed something that better met our current and future needs.
Potential solutions to our problems with Celery and RabbitMQ
With the problems outlined above, we considered the following solutions:
- Change the Celery broker from RabbitMQ to Redis or Kafka. This would allow us to continue using Celery, with a different and potentially more reliable backing datastore.
- Add multi-broker support to our Django app so consumers could publish to N different brokers based on whatever logic we wanted. Task processing will get sharded across multiple brokers, so each broker will experience a fraction of the initial load.
- Upgrade to newer versions of Celery and RabbitMQ. Newer versions of Celery and RabbitMQ were expected to fix reliability issues, buying us time as we were already extracting components from our Django monolith in parallel.
- Migrate to a custom solution backed by Kafka. This solution takes more effort than the other options we listed, but also has more potential to solve every problem we were having with the legacy solution.
Each option has its pros and cons:
| Option | Pros | Cons |
| Redis as broker |
|
|
| Kafka as broker |
|
|
| Multiple brokers |
|
|
| Upgrade versions |
|
|
| Custom Kafka solution |
|
|
Our strategy for onboarding Kafka
Given our required system uptime, we devised our onboarding strategy based on the following principles to maximize the reliability benefits in the shortest amount of time. This strategy involved three steps:
- Hitting the ground running: We wanted to leverage the basics of the solution we were building as we were iterating on other parts of it. We liken this strategy to driving a race car while swapping in a new fuel pump.
- Design choices for a seamless adoption by developers: We wanted to minimize wasted effort on the part of all developers that may have resulted from defining a different interface.
- Incremental rollout with zero downtime: Instead of a big flashy release being tested in the wild for the first time with a higher chance of failures, we focused on shipping smaller independent features that could be individually tested in the wild over a longer period of time.
Hitting the ground running
Switching to Kafka represented a major technical change in our stack, but one that was sorely needed. We did not have time to waste since every week we were losing business due to the instability of our legacy RabbitMQ solution. Our first and foremost priority was to create a minimum viable product (MVP) to bring us interim stability and give us the headroom needed to iterate and prepare for a more comprehensive solution with wider adoption.
Our MVP consisted of producers that published task Fully Qualified Names (FQNs) and pickled arguments to Kafka while our consumers read those messages, imported the tasks from the FQN, and executed them synchronously with the specified arguments.
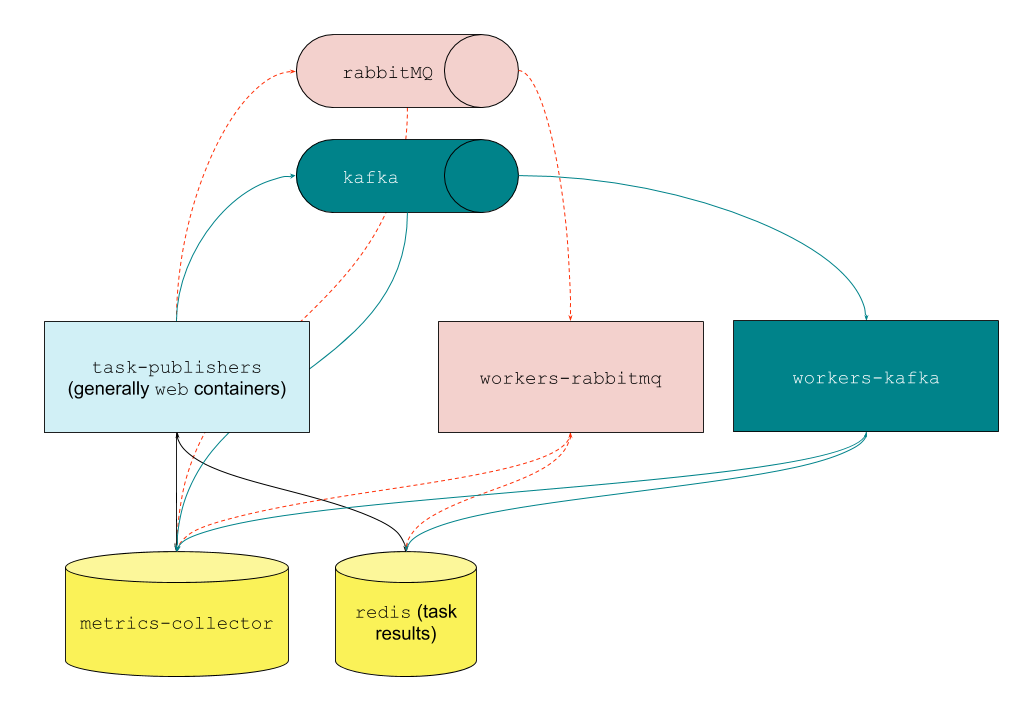
Design choices for a seamless adoption by developers
Sometimes, developer adoption is a greater challenge than development. We made this easier by implementing a wrapper for Celery’s @task annotation that dynamically routed task submissions to either system based on dynamically-configurable feature flags. Now the same interface could be used to write tasks for both systems. With these decisions in place, engineering teams had to do no additional work to integrate with the new system, barring implementing a single feature flag.
We wanted to roll out our system as soon as our MVP was ready, but it did not yet support all the same features as Celery. Celery allows users to configure their tasks with parameters in their task annotation or when they submit their task. To allow us to launch more quickly, we created a whitelist of compatible parameters and chose to support the smallest number of features needed to support a majority of tasks.
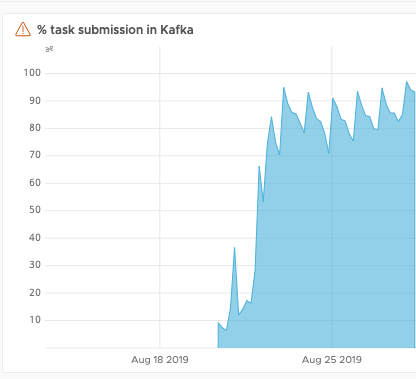
As is seen in Figure 2, with the two decisions above, we launched our MVP after two weeks of development and achieved an 80% reduction in RabbitMQ task load another week after launch. We dealt with our primary problem of outages quickly, and over the course of the project supported more and more esoteric features to enable execution of the remaining tasks.
Incremental rollout, zero downtime
The ability to switch Kafka clusters and switch between RabbitMQ and Kafka dynamically without business impact was extremely important to us. This ability also helped us in a variety of operations such as cluster maintenance, load shedding, and gradual migrations. To implement this rollout, we utilized dynamic feature flags both at the message submission level as well as at the message consumption side. The cost of being fully dynamic here was to keep our worker fleet running at double capacity. Half of this fleet was devoted to RabbitMQ, and the rest to Kafka. Running the worker fleet at double capacity was definitely taxing on our infrastructure. At one point we even spun up a completely new Kubernetes cluster just to house all of our workers.
During the initial phase of development, this flexibility served us well. Once we had more confidence in our new system, we looked at ways to reduce the load on our infrastructure, such as running multiple consuming processes per worker machine. As we transitioned various topics over, we were able to start reducing the worker counts for RabbitMQ while maintaining a small reserve capacity.
No solution is perfect, iterate as needed
With our MVP in production, we had the headroom needed to iterate on and polish our product. We ranked every missing Celery feature by the number of tasks that used it to help us decide which ones to implement first. Features used by only a few tasks were not implemented in our custom solution. Instead, we re-wrote those tasks to not use that specific feature. With this strategy, we eventually moved all tasks off Celery.
Using Kafka also introduced new problems that needed our attention:
- Head-of-the-line blocking which resulted in task processing delays
- Deployments triggered partition rebalancing which also resulted in delays
Kafka’s head-of-the-line blocking problem
Kafka topics are partitioned such that a single consumer (per consumer group) reads messages for its assigned partitions in the order they arrived. If a message in a single partition takes too long to be processed, it will stall consumption of all messages behind it in that partition, as seen in Figure 3, below. This problem can be particularly disastrous in the case of a high-priority topic. We want to be able to continue to process messages in a partition in the event that a delay happens.
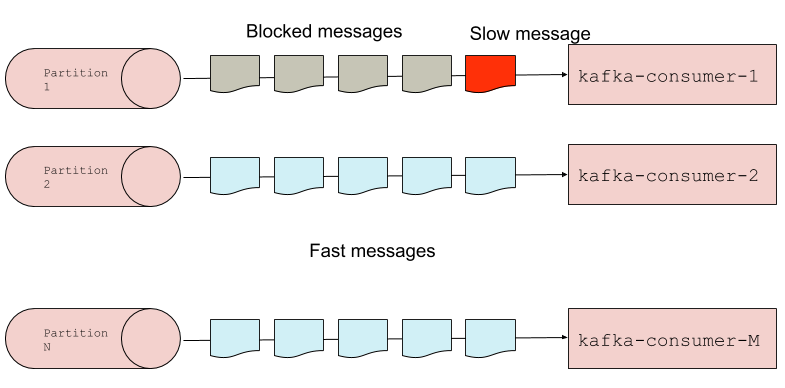
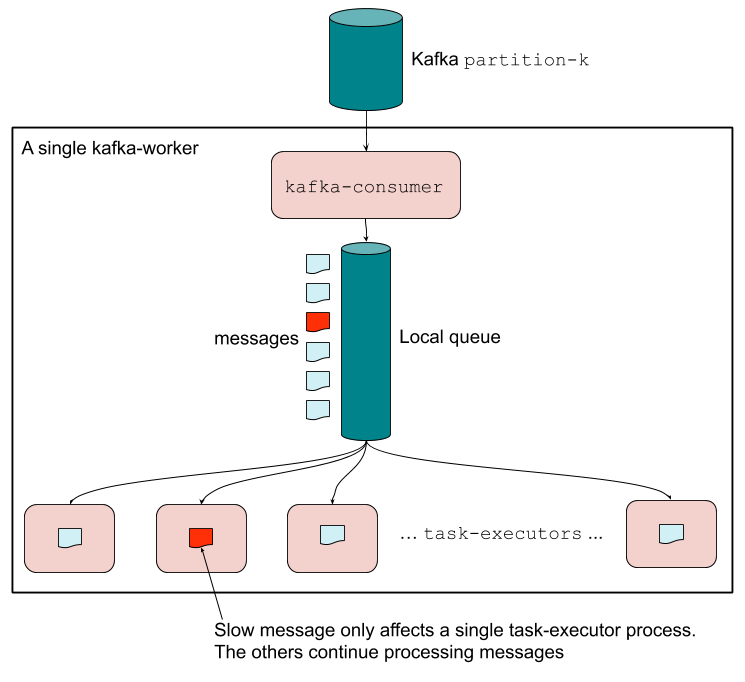
While parallelism is, fundamentally, a Python problem, the concepts of this solution are applicable to other languages as well. Our solution, depicted in Figure 4, below, was to house one Kafka-consumer process and multiple task-execution processes per worker. The Kafka-consumer process is responsible for fetching messages from Kafka, and placing them on a local queue that is read by the task-execution processes. It continues consuming till the local queue hits a user-defined threshold. This solution allows messages in the partition to flow and only one task-execution process will be stalled by the slow message. The threshold also limits the number of in-flight messages in the local queue (which may get lost in the event of a system crash).
The disruptiveness of deploys
We deploy our Django app multiple times a day. One drawback with our solution that we noticed is that a deployment triggers a rebalance of partition assignments in Kafka. Despite using a different consumer group per topic to limit the rebalance scope, deployments still caused a momentary slowdown in message processing as task consumption had to stop during rebalancing. Slowdowns may be acceptable in most cases when we perform planned releases, but can be catastrophic when, for example, we're doing an emergency release to hotfix a bug. The consequence would be the introduction of a cascading processing slowdown.
Newer versions of Kafka and clients support incremental cooperative rebalancing, which would massively reduce the operational impact of a rebalance. Upgrading our clients to support this type of rebalancing would be our solution of choice going forward. Unfortunately, incremental cooperative rebalancing is not yet supported in our chosen Kafka client yet.
Key wins
With the conclusion of this project, we realized significant improvements in terms of uptime, scalability, observability, and decentralization. These wins were crucial to ensure the continued growth of our business.
No more repeated outages
We stopped the repeated outages almost as soon as we started rolling out this custom Kafka approach. Outages were resulting in extremely poor user experiences.
- By implementing only a small subset of the most used Celery features in our MVP we were able to ship working code to production in two weeks.
- With the MVP in place we were able to significantly reduce the load on RabbitMQ and Celery as we continued to harden our solution and implement new features.
Task processing was no longer the limiting factor for growth
With Kafka at the heart of our architecture, we built a task processing system that is highly available and horizontally scalable, allowing DoorDash and its customers to continue their growth.
Massively augmented observability
Since this was a custom solution, we were able to bake in more metrics at almost every level. Each queue, worker, and task was fully observable at a very granular level in production and development environments. This increased observability was a huge win not only in a production sense but also in terms of developer productivity.
Operational decentralization
With the observability improvements, we were able to templatize our alerts as Terraform modules and explicitly assign owners to every single topic and, implicitly, all 900-plus tasks.
A detailed operating guide for the task processing system makes information accessible for all engineers to debug operational issues with their topics and workers as well as perform overall Kafka cluster-management operations, as needed. Day-to-day operations are self-serve and support is rarely ever needed from our Infrastructure team.
Conclusion
To summarize, we hit the ceiling of our ability to scale RabbitMQ and had to look for alternatives. The alternative we went with was a custom Kafka-based solution. While there are some drawbacks to using Kafka, we found a number of workarounds, described above.
When critical workflows heavily rely on asynchronous task processing, ensuring scalability is of the utmost importance. When experiencing similar issues, feel free to take inspiration from our strategy, which granted us 80% of the result with 20% of the effort. This strategy, in the general case, is a tactical approach to quickly mitigate reliability issues and buy sorely needed time for a more robust and strategic solution.
Acknowledgments
The authors would like to thank Clement Fang, Corry Haines, Danial Asif, Jay Weinstein, Luigi Tagliamonte, Matthew Anger, Shaohua Zhou, and Yun-Yu Chen for contributing to this project.












This was a really interesting read! After moving to Kafka, how did you solve the scheduled / delayed task processing?
Hi Robin, Thanks for your feedback! We’ve moved to using Cadence: https://github.com/uber/cadence for scheduled tasks. Here is another blog post on how we’re using Cadence for scheduled tasks: https://doordash.engineering/2020/08/14/workflows-cadence-event-driven-processing/
It’s a great read and looks like a well informed decision. However I wonder how much of the decision was motivated by the “let’s try something new!” spirit. I’m asking this because your analysis suggests that you did not look for root causes, but rather for reasons to change. For example you say scaling rabbitmq was not an option because the single node was already at max. Yet then you introduce Kafka which requires a multi-node set up to be effective. So you are solving your problem – maxed out node capacity – with a new technology using a completely new setup, which might have worked for rabbitmq too. Also you say that celery workers were having challenges in bursted parallel processing but you did not want to try a multi broker setup (I presume you mean multi vhosts). Yet you introduce Kafka which does exactly the same with topics and partitions. Setting up the same for celery would have been a mere configuration change – create vhosts in rabbitmq and connect accordingly from celery. Further you say you implemented a new component, to replace, yet semantically similar to celery, minus some features. That’s not conclusive. In fact its likely that you will run into more issues down the line because celery had some 10+ years of testing and is known to be stable and scalable. Not critizing, just wondering.
Thanks for the comment. The decision to use Kafka vs making RabbitMQ work fundamentally boiled down to the fact our engineers have hands-on experience scaling Kafka (and it’s consumers). While Kafka, was a new investment at DoorDash at the time, it was not new to many engineers, and the choice to use Kafka was more about using something we knew would work vs trying something new. In our eyes, it was, in fact, the less risky option.
As for effectively re-writing some components of celery, yes there was a risk there, but we mitigated it by implementing the smallest set of features needed and the benefit of improved visibility was worth the risk.
Thanks for your reply. Choosing a technology because skills are available is of course a viable decision criteria. If that’s the driving force why not state so upfront? All the decision tables, pros & cons are pretty much moot after that, certainly biased (been there, done that 🙂
Above all why hit on RabbitMQ and Celery? Your team knows Kafka in and out, you like it. It solved your problem. Great! That all speaks to the validity of your choice.
So why bother writing a comment? I just think your article provides an unfair representation of the merits of the RabbitMQ + Celery combo. Especially because much of the criticism does not hold up to scrutiny. For example, RabbitMQ provides a lot of metrics, even presents it nicely & live in the management dashboard. Also available via its API and admin commands. I have a hard time believing you did not find these metrics useful Especially because it seems so much more convenient than with Kafka. Also it scales well horizontally, no Zookeeper mess and config fiasko that IMHO is Kafka (as is common for Apache projects). Further, Celery does very much provide insights into what is going on, via cli and its API, allows easy remote control. Has good logging support. Also scales very easily horizontally and vertically, allows both topics and partioning, as well as providing many options for QaS and flow control. Noteably with almost no configuration. I doubt you were able to replicate that in your own implementation, and if you did it speaks to Celery’s advantage even more.
Anyhow. Please take my reply as constructive critisism. I respect your decision & appreciate the various constraints. Very much enjoyed reading your article.
This is a nice article, yes Celery doesn’t integrate with Kafka very well. My guess the major problem is the head-off-the-line in Kafka.
I am curious on the solution to the head-off-the-line problem in kafka, when the parallel execution tasks finished in different order, how does the DoorDash decide which message offset to commit back to the Kafka broker? By not committing by the original order of the offset may cause message loss when the app crashed.