
Building quality recommendations and personalizations requires delicately balancing what is already known about users while recommending new things that they might like. As one of the largest drivers of DoorDash’s business, the homepage contributes a significant portion of our total conversions. Its layout, as shown in Figure 1, is meant to inspire customers to order their favorite food and discover new merchants. Given the homepage’s limited real estate, we wanted to add personalization features to improve the customer experience through increasing the relevance of every item presented there.
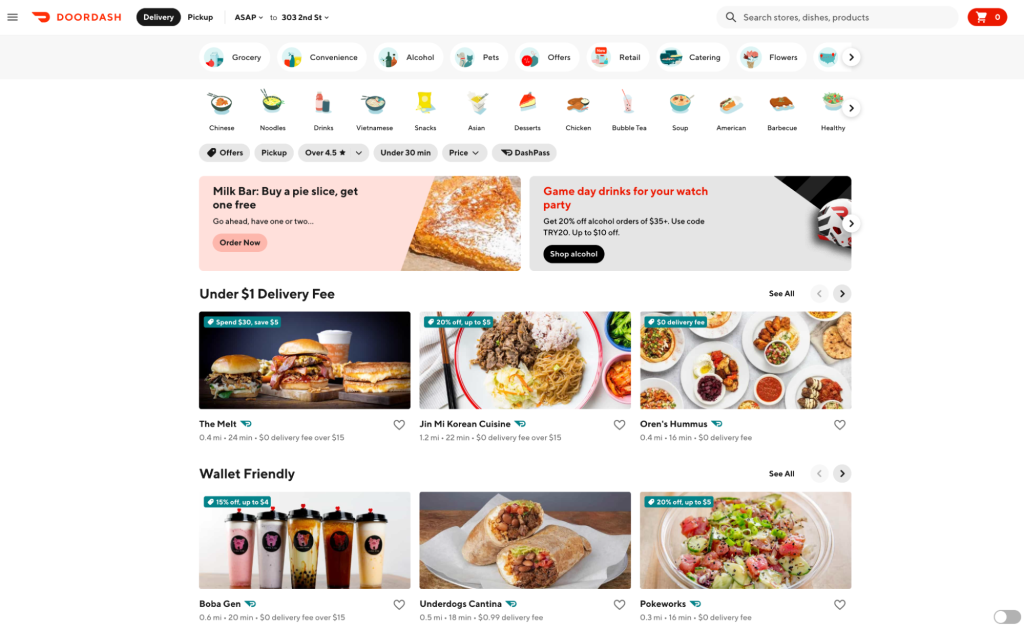
Building personalized recommendations is challenging. Each person is nuanced in what they like and that varies based on how they feel when ordering. Personalized recommendations requires knowing each consumer well enough to surface the most relevant merchants in the space constrained homepage, typically from more than 1,000 merchants available. Additionally, our recommendation must adapt quickly to changing consumer interests at different times of the day, day of the week, and locations. Personalized recommendation at DoorDash involves using both what we already know about users ( also known as exploitation) and showing users new things to better understand what they like (also known as exploration) to improve consumer experience.
In this post, we will first give a high-level overview of how our homepage rankings work and then zero in on how our model balances exploitation and exploration during ranking to optimize the consumer experience while simultaneously improving fairness for merchants. After introducing both the challenges and opportunities in relevance ranking for mixed types of homepage entities, we present our machine learning (ML) solution, a deep-learning-based learn-to-rank (LTR) model — universal ranker (UR). We discuss the need to go beyond exploitation, sharing our exploration approach based on the concept of upper confidence bound (UCB), a reinforcement learning method known for solving multi-armed bandit (MAB) problems. Finally, we illustrate a ranking framework integrating UR and UCB, and discuss how we make intelligent trade-offs between exploitation and exploration in our homepage recommendations.
What’s behind DoorDash’s homepage recommendation
From retrieving information of thousands of stores to presenting a unique experience for consumers, DoorDash’s homepage recommendation can be divided into three major stages:
- First pass ranking, or FPR, is the first part of the retrieval stage and includes:
- Selecting no more than 1,200 candidates from ElasticSearch that are most relevant to the consumer experience among all stores
- Satisfying a combination of strategies, such as including certain popular stores while guaranteeing diversity across verticals (for example, restaurants, convenience and grocery stores, or retail stores)
- Second pass ranking, or SPR, filters and pre-ranks those candidates, ultimately:
- Choosing up to 50 for the first page of the store feed
- Ranking stores/items within horizontally scrollable carousels, each of which offers different subsets of candidates (for example, a “National Favorites” carousel might contain popular chain stores while the “Now on DoorDash” carousel might suggest newly onboarded local stores)
- Final ranking, or FR, is the concluding stage, resulting in vertical rankings of all available carousels and stores on the first page of the store feed.
Our efforts here focus on the FR stage, which determines the order of contents shown to consumers when they scroll vertically.
Subscribe for weekly updates
Contending with comparing different entities on the DoorDash homepage
To better illustrate the complexity at the FR stage, it's helpful to introduce how the DoorDash homepage showcases entities through its organization and layout. We define an entity as any content module that can be placed into a single slot on the homepage, such as a merchant, an item, or an offer. As shown in Figure 2, a single entity could be a store or an item while a nested entity, or carousel, contains ordered individual entities such as the “Now on DoorDash” store carousel or an item carousel such as “Most Ordered Dishes Near You.”
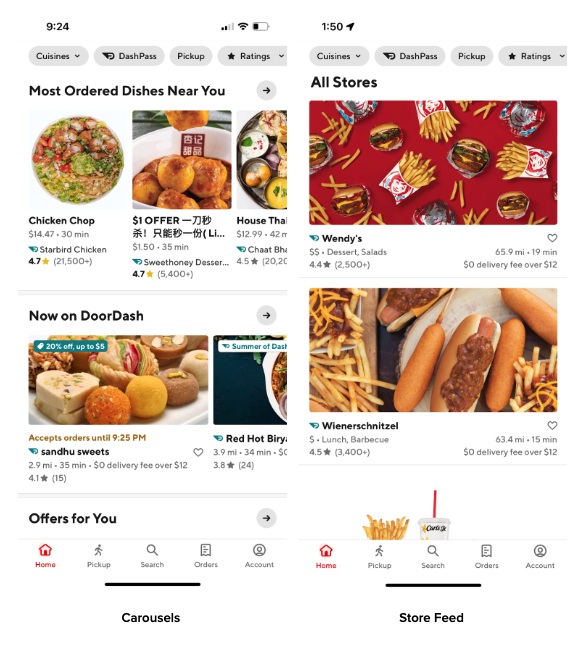
As discussed, the total candidates for recommendation already have been significantly narrowed in the initial two stages to fewer than 50 carousels — the actual number varies at different locations and time of day — and no more than 50 individual stores for the first page of the store feed. However, these candidates consist of a mixture of different entity types, which creates huge challenges for building ranking models.
Difficulties with scalability and calibration
It is not practical or scalable to build a dedicated ranking model for each entity type, both because a new model is required each time a different entity type lands on the homepage and because each model subsequently requires maintenance going forward.
What’s more, even if we built these dedicated models, it is difficult to calibrate and compare the scores they produce for different entities. For example, say we want to recommend highly relevant and good-quality Japanese restaurants and dishes to consumers who often order sushi or ramen. While it might be straightforward to compare relevance between two restaurants, comparing a Japanese restaurant with a store carousel consisting of more than 10 popular Asian restaurants and their dishes is a nontrivial task. That challenge demands comparing apples and oranges.
Enhancing relevance and efficiency opens opportunities
The ability to rank mixed entity types helps unlock the potential for more relevant homepage recommendations.
On our existing homepage, we have a fixed order for entities:
- nested carousel entities come first
- single-store entities come second
This worked well initially in 2020 when there were only half a dozen carousels; consumers could either scroll horizontally to engage with a favorite carousel or vertically to move quickly to individual stores for more options. But the number of carousels has exploded to more than 30 as of the third quarter of 2022, making it hard for consumers to see any individual stories below the carousels. The old homepage organization makes for a suboptimal consumer experience today. While we could place highly relevant stores just below the carousels, the distance from the beginning of the consumer journey sharply lowers their visibility. Switching positions of stores and carousels could result in low-relevance stores getting top billing, wasting precious impression opportunities.
To address the issue, we launched a new UI framework. It allows intermixing experiences on the homepage to unlock the potential for more optimal homepage recommendations; for instance, a more relevant store could be ranked higher than a less relevant carousel overall, as shown by the “New” UX in Figure 3. However, this new experience also has created challenges for the ML ranking model. Our solution has been to develop a single model that essentially can compare apples and oranges to showcase the best products to consumers.

Building a universal ranker to empower exploitation
To improve homepage engagement, we built the UR to provide consistent ranking across a variety of entities, prioritize better relevancy, and shorten the consumer’s shopping journey. As noted earlier, this LTR model uses a deep neural network to leverage the learnings from the deep learning recommendation model and “Wide & Deep” learning, which deploys jointly trained wide linear models and deep neural networks. The UR jointly ranks vertical positions for mixed types of entities by order of their pConv — probability of conversion, which is how we measure the relevance of a recommendation.
The most complex and universal aspect of developing our UR was figuring out how to compare different entities in different places. Ultimately, we accomplished this by creating a consistent relationship across all types of entities. From high to low, we define three hierarchical levels of entities: 1) a store carousel, 2) an individual store/item carousel, and 3) an individual item, where a higher-level entity can be represented by an ordered sequence of lower-level ones. For example, a store carousel could be viewed as an ordered list of stores, each of which also could be viewed as an ordered list of items. With the bridge through individual stores, a store carousel can then be viewed as an ordered, nested list of items. The model ranks a store as a carousel with only one store and an item within that store as a carousel with only one store and one item. With this sequential relationship, we can then construct the features of a high-level entity from the low-level ones it contains. Using a feature “f” as an example, we build the feature for an individual store and a store carousel as follows:
- individual store 1: [f_1, padding, padding]
- carousel with 3 stores: [f_1, f_2, f_3]
In addition to the padding/clipping approach, where we need to define a pre-fixed sequence length, we can also incorporate a layer such as LSTM to transform the sequential features into the same dimensions as individual ones, which the model then can easily use.
The UR’s features can be divided into four major categories:
- Entity-related features such as cuisine type, price range, popularity, quality, and rating
- Consumer-related features such as cuisine/taste preference, vegan status, and affordability
- Consumer-entity engagement features such as view/click/order history, rating, and reorder rate
- Context-related features such as delivery ETA/distance/fee, promotion, day part, week part, holiday, and weather conditions
In addition to traditional numerical and categorical feature types, we heavily used embeddings across all the feature categories, including both pre-trained embeddings from existing ML models and embedding layers trained as part of the model itself. The ETL for the batch features was developed and maintained through our internal tool Fabricator and the LTR UR model was implemented in PyTorch.
With this model, we can show consumers items they might like despite the varying entity challenges. The next step would be to expand our model beyond what we think they like so we can broaden our understanding of customer preferences.
Exploring beyond exploitation
Only focusing on exploitation can lead consumers into the so-called filter bubble/ideological frame problem. This occurs when existing consumers begin to perceive only a small subset of merchants with whom they are already familiar, creating a self-fulfilling prophecy in which consumers buy primarily similar items. Recommendations for new consumers might be biased toward their initial engagement rather than their true preferences; their homepage may be flooded with very similar options, reducing the amount of time left to explore.
This exploitation also may delay response to consumer preference changes over time because exploitation models have strong momentum for previous behaviors and are slow to adapt to new information. Consumers also could become bored with what they perceive as a stale homepage; the lack of inspiration could depress order rates. On the merchant side, over-exploitation could cause fairness issues over time as popular merchants become ever more dominant while new merchants recede into the platform’s background.
Enabling exploration using upper confidence bound
To overcome these problems, we introduced a reinforcement learning approach based on a UCB algorithm to enable consumers to explore. In a greedy manner, the UCB algorithm favors exploration actions with the strongest potential to maximize rewards, where potential is quantified in terms of uncertainty. While there are various UCB variants with different assumptions and complexities, the core concept involves the expected reward and its associated uncertainty for a given action:
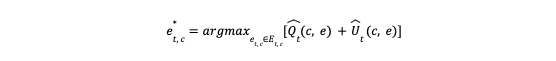
where t is the total times of all the previous trials of recommending an entity e to a consumer c.
e* t, c is the optimal entity we want to recommend to a consumer c at a time t;
e t, c Et, c are an individual entity and the entire entity set available to consumer c at time t, respectively;
Q̂ t(c, e) is the expected reward for consumer c on an entity e;
Û t(c, e) is the uncertainty of the reward for a consumer c on an entity e.
Based on Hoeffding’s inequality for any bounded distribution, this approach guarantees that with only a probability of e -2tÛt(c, e)2 could the actual reward Qt(c, e) be higher than the estimated UCB of Qt(c, e)+Ut(c, e). If we choose a very small constant p for e-2tÛt(c, e)2, then we have:
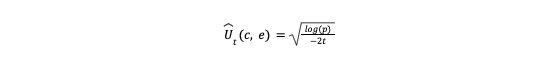
To have higher confidence in our UCB estimation as we continue to collect more reward (conversion) data from our recommendations, we can reduce the threshold by setting p=T-4 following the UCB1 algorithm:
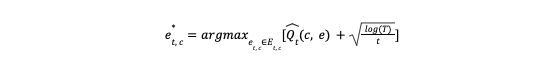
where T is the total trial times for consumer c on all recommended entities, while t is the total trial times of entity e to consumer c.
How we combined exploitation and exploration
It is neither feasible nor optimal to directly implement the UCB in its original form because:
- Each consumer can choose from thousands of stores and hundreds of thousands of items at a certain location and time, making it impossible to try each of them and hampering collection of cumulative conversion data to estimate the pConv.
- Estimating the expected pConv for entities with mixed types adds further complexity
- The recommendation engine produces a ranked list of entities for each consumer. But because a single app window can only show a few entities and because each consumer can choose how deep they wish to browse/scroll, there’s uncertainty around how many of the recommended entities will receive effective consumer feedback.
- When introducing fresh options for a consumer, we need to control uncertainty carefully so that they do not add confusion or interrupt the consumer experience.
Given these considerations, our final solution was to integrate the UR into the UCB algorithm. This allows us to make scalable and smart trade-offs between exploitation and exploration, allowing fresh choices for consumers without disturbing their routing experience.
Defining the composite model
We define the reward from any recommendation as the consumer conversion within a certain time period; hence, the expected reward essentially is evaluated by the expected pConv for any consumer-entity pair. The consumer-entity impression is used to track the effective recommendation trial and estimate the uncertainty of the corresponding pConv. The final UCB score is then obtained by blending the UR score (pConv) with the uncertainty. Data driving the UR and uncertainty is refreshed daily; the entire process could be viewed from a Bayesian perspective. Each day, we assume the prior distribution for the pConv variable has the mean and standard deviation of the current UR score and uncertainty. We then compute the posterior distribution with another day’s consumer-entity engagement data:
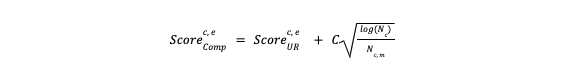
where Nc is the total impressions for the consumer c on all recommended entities within a certain time period
N c, m is the impressions between consumer c and entity e within a certain time period C is the exploration coefficient
The uncertainty increases slowly and logarithmically as a consumer’s total impression goes up but decays rapidly with the linear relationship as the specific impression for a certain entity increases. This relative relationship benefits the ranking system in two ways:
- It improves freshness when a consumer mostly engages with a few entities (for example, the top 10 on the homepage). Although the UR scores for these entities remain high, their uncertainties will continue to drop rapidly. On the other hand, those entities without impressions would have their uncertainties continue to increase until they are large enough to force their way into the top 10.
- It aids quick homepage personalization when a consumer enjoys broad exploration. With multiple impressions for various entities, there is a consistent uncertainty drop for each of them such that the composite score converges to its UR score, which is sensitive to positive engagement signals such as clicks, orders, and good ratings.
We also add the exploration coefficient C for the uncertainty because we are less interested in its accuracy but more in its scale, which directly determines how much disturbance will be introduced to the existing ranking (for example, how many new entities are surfaced higher and how different their positions are historically). The optimal C is then determined later through online experiments.
Integrating all models into a ranking framework
The DoorDash homepage ranking framework with all these pieces put together is shown in Figure 4. The exploitation component includes the FPR, SPR, and UR, while the exploration component introduces uncertainty to the expected pConv predicted by the UR. By continuing to collect and update the engagement data through daily refreshed features, we can generate a more accurate mean of the pConv while building more confidence in our uncertainty estimation.
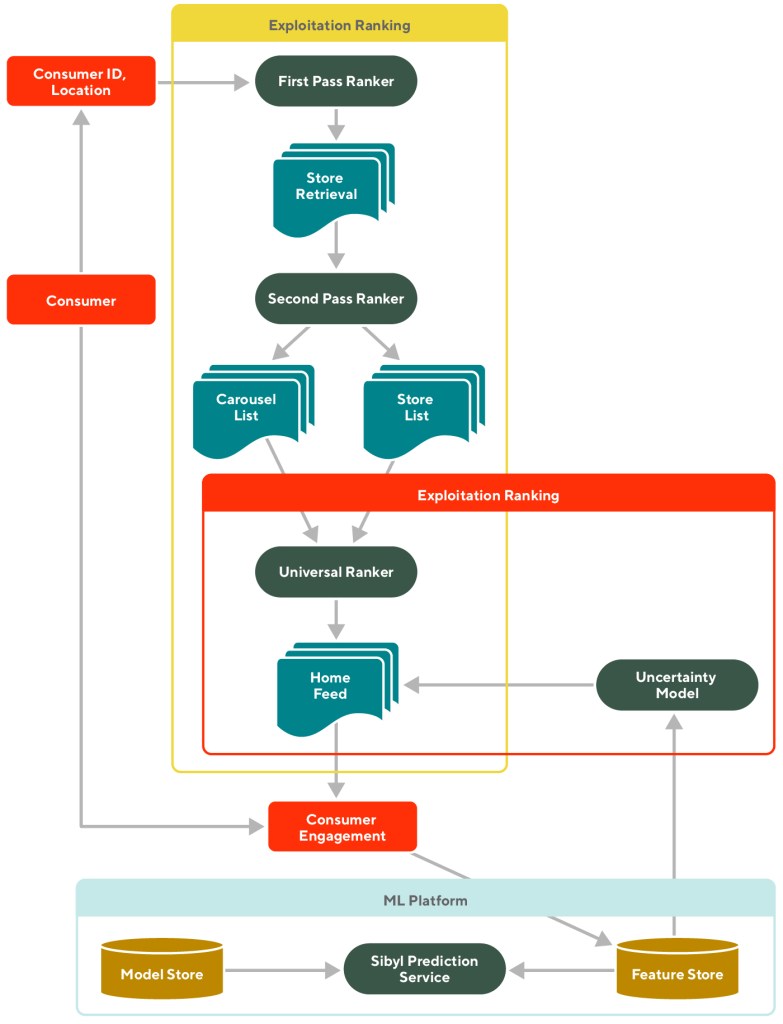
Enabling a better homepage experience
With the newly developed framework, we give consumers an improved dynamic experience, including:
- Keeping the most relevant entities at the top (high UR scores)
- Downranking the entities that are somehow relevant (median UR scores) but have way too many impressions (low uncertainties)
- Trying new entities from lower positions (low UR scores) that have little chance to be shown to the consumers (high uncertainties)
- Prioritizing the newly tried entities if they receive positive feedback from consumers as measured by orders or good ratings, which also represents improved UR scores with dropped uncertainties
- Deemphasizing newly tried entities if there is no positive feedback from consumers — for instance, only views but no further actions. This represents low UR scores with dropped uncertainties
As can be seen in Figure 5, the change primarily impacts existing consumers who previously have browsed entities on our platform. There is little impact on new consumers for whom we have no engagement data. We show the example experience using carousel and store feeds separately because the homepage experience with mixed entities remains a work in progress.
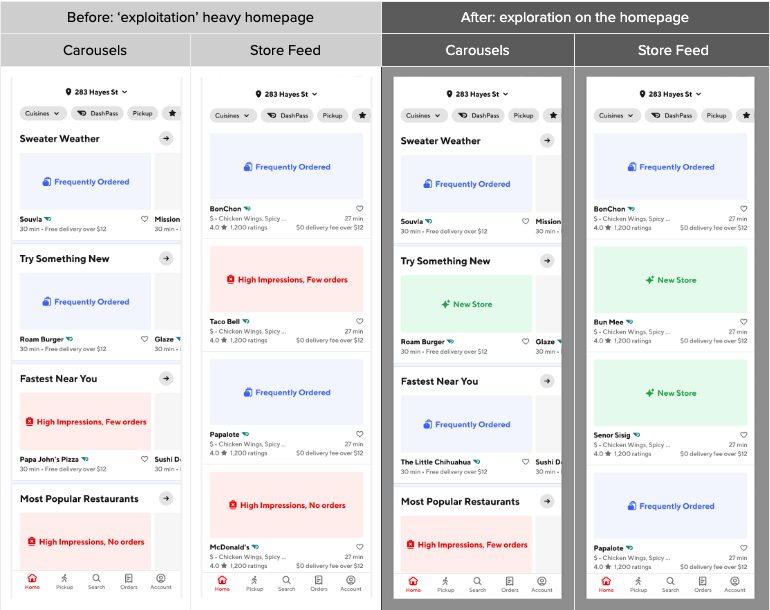
With the developed framework, we observe consistent improvements in our online experiments. The new experience drives more consumers to engage with our recommendations and convert on the homepage. More consumers are interested in trying new merchants and items they never ordered before, which not only enriches their experience but also creates more opportunities for our local or new merchants rather than our enterprise ones.
Conclusion
We have demonstrated here the challenges, opportunities, and goals for homepage recommendations at DoorDash. Two machine learning approaches — including a deep-learning LTR UR model and a reinforcement learning algorithm UCB — have been integrated into our existing ranking framework. Through online experiments, we have proven that the ranking framework can efficiently rank various entities with a smart trade-off between exploitation and exploration to optimize consumer experience, improve marketplace diversity and fairness, and drive DoorDash’s long-term growth.
Our work to date shows positive results, but there are still potential improvements we can make. So far, we have only introduced exploration to vertical rankings. But it could be promising for horizontal ranking within high-level entities such as store and item carousels at the SPR stage and possibly for candidate retrieval during the FPR stage. Note, too, that the current exploration coefficient is uniform for all consumers; we could personalize it for different consumers based on their shopping behavior and exploration sensitivity. Ultimately, Thompson sampling could be an alternative to test against the current UCB approach.
Acknowledgments
Special thanks to Josh Zhu, Jay Zhang, Parul Khurana, and Janice Hou who worked together to make this exciting work happen! Also thanks Di Li, Sandor Nyako, Eric Gu, Xiaochang Miao, Han Shu, Matthieu Monsch, Abhi Ramachandran, Chen Dong, Chun-Chen Kuo, Mengjiao Zhang, Kunal Moudgil, Mauricio Barrera, Melissa Hahn, Kurt Smith, Meng Chen, and Wu Han for sharing their insights on the development and support for the execution of the ideas in this blog post. Our gratitude also goes to Elena Lin and Jessica Zhang for the data-driven insights and for helping us develop the experiment strategy and measurement framework. Thanks Ezra Berger for the continuous support, review, and editing of this article.












Thanks for sharing! This is a really interesting work. I am still a little bit confused about the UR model in terms of how it solves the problem of different entities. Here are some of my questions:
1. Let’s assume to use the padding/clipping approach here. does that mean it will be a list for each entity-related feature? e.g. entity cuisine type for an individual store will be [indian, padding, padding]?
2. how to aggregate the entity features? the cuisine feature may be good to characterize a store but may be different to characterize a carousel. what is our method?
3. The key idea here as what you’ve written is “construct the features of a high-level entity from the low-level ones it contains”, but I see you use store-level features to represent a carousel and still use store-level features to represent an individual store, so do you also use the store-level feature to represent an item? Does that misalign with what you have written?
4. Could you talk a bit more about how to use LSTM here?
Sorry for those long questions but super look forward to your replies! Thanks again!
Hi Victor,
Thanks for your great questions. Here are some of my thoughts for your reference.
1. Yes, it will be an ordered sequence of features corresponding to each entity, and your example is correct.
2. We have features at different entity levels. Using scoring a store carousel as an example, we have store-level features which will be passed as an ordered sequence; we could also have carousel-level and consumer-level features, which are not sequences.
3. For ranking items, we need to have item-level features as well. In addition, we also keep the store-level features as they would give better context info of the items. For example, when comparing two burgers from different restaurants, whether they are from one popular merchant or another could still make a difference for our consumers.
4. LSTM can be used to extract both temporal and spatial (our use case here) sequence features. For example, we have a sequence of store-level features for a carousel, similar to use mean/max pulling, we can also use LSTM to pull them into an aggregated layer.