
There have been many benefits gained through DoorDash’s evolution from a monolithic application architecture to one that is based on cells and microservices. The new architecture has reduced the time required for development, test, and deployment and at the same time has improved scalability and resiliency for end-users including merchants, Dashers, and consumers. As the number of microservices and back-ends has grown, however, DoorDash has observed an uptick in cross-availability zone (AZ) data transfer costs. These data transfer costs — incurred on both send and receive — allow DoorDash to provide its end users a highly available service that can withstand degradations of one or more AZs.
The cost increase prompted our engineering team to investigate alternative ways to provide the same level of service more efficiently. In this blog post, we describe the journey DoorDash took using a service mesh to realize data transfer cost savings without sacrificing service quality.
DoorDash traffic architecture
Before we dive into our solution, let’s review DoorDash’s traffic infrastructure.
Cell-based architecture: As shown in Figure 1 below, our traffic architecture follows a cell-based design. All microservice pods are deployed in multiple isolated cells. Every service has one Kubernetes deployment per cell. To ensure isolation between cells, intercellular traffic is not permitted. This approach enables us to reduce the blast radius of a single-cell failure. For singleton services or those not migrated to the cell architecture, deployment occurs in a singular global cell. Internal Envoy routers allow communication between the global cell and replicated cells.
Kubernetes cluster deployment: Each cell consists of multiple Kubernetes clusters; each microservice is deployed exclusively to one cluster within a given cell. This design ensures scalability and reliability while aligning with our cell-based architecture.
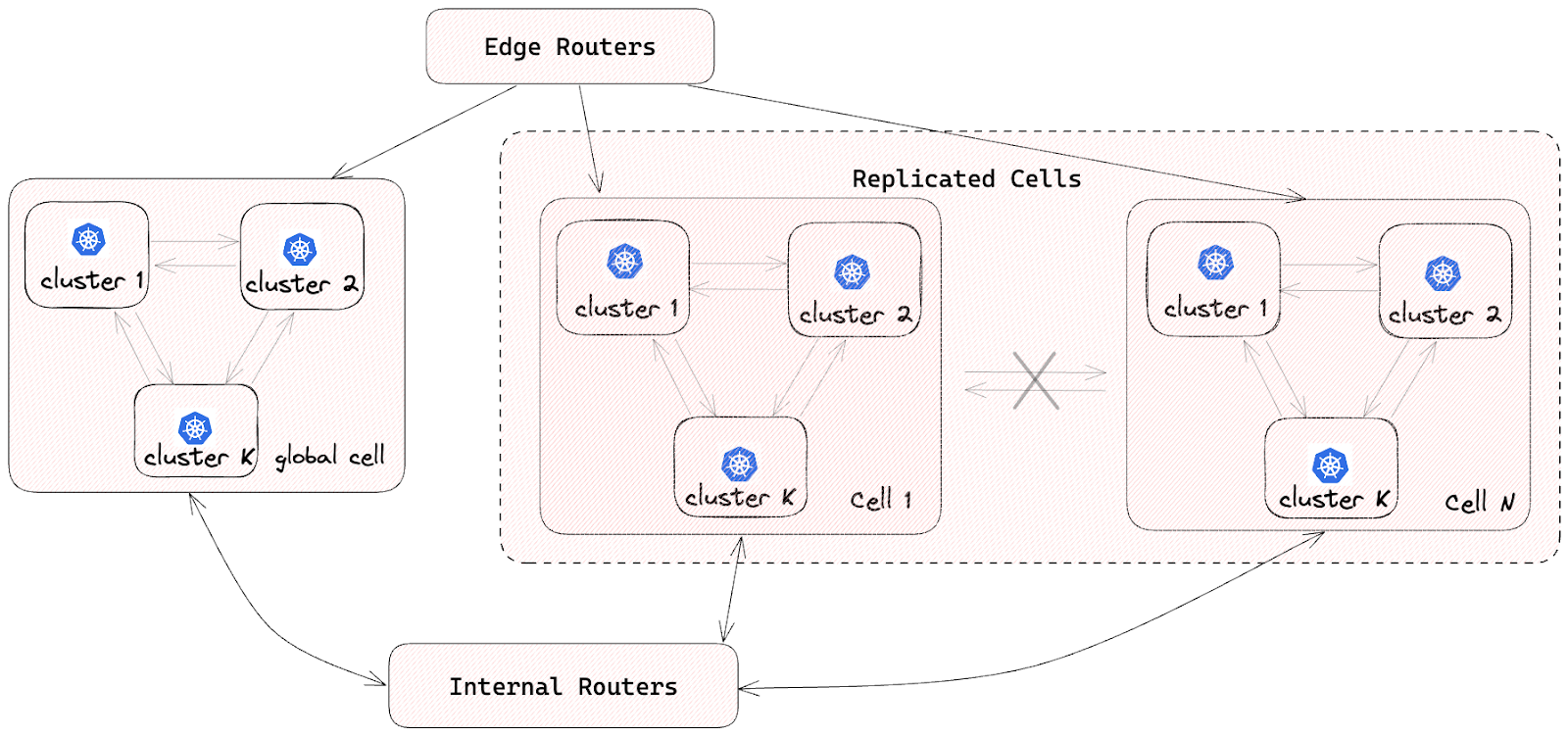
High availability: To enhance availability and fault tolerance, each Kubernetes cluster is deployed across multiple AZs. This practice minimizes disruptions caused by an outage of one or more AZs.
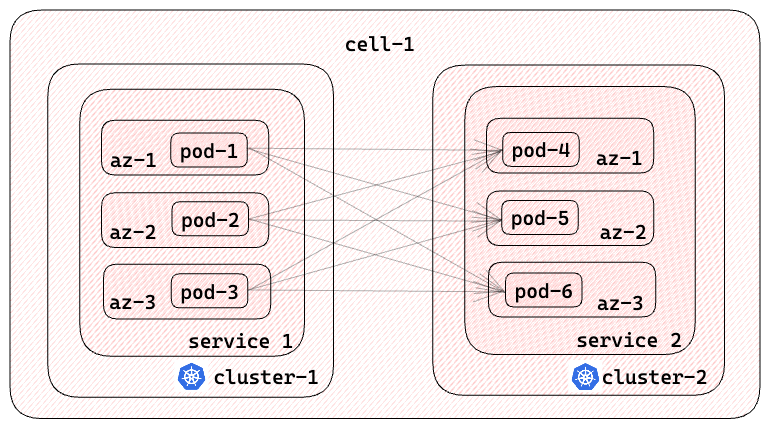
Direct communication in a flat network: Leveraging AWS-CNI, microservice pods in distinct clusters within a cell can communicate directly with each other. This flat network architecture streamlines communication pathways, facilitating efficient interactions between microservices.
Custom multi-cluster service discovery: Our custom service discovery solution, DoorDash data center Service Discovery, or DDSD, provides a custom DNS domain to support multi-cluster communication. Clients leverage DNS names to dynamically discover all pod IP addresses of desired services. DDSD’s functionality is similar to Kubernetes headless services, but it works for inter-cluster communication as well. For instance, a client in a different cluster can use payment-service.service.prod.ddsd to retrieve all pod IP addresses associated with the payment service.
Client-side load balancing: Service mesh is responsible for client-side load balancing. For services not onboarded to service mesh, however, load balancing occurs on the client application side.
Figure 2 depicts the four characteristics outlined above:
Service mesh architecture: DoorDash’s service mesh as outlined in Figure 3, which is deployed to each cell, adopts a sidecar container design pattern, leveraging Envoy proxy as the data plane. We’ve built our own xDS-based control plane to manage Envoy configurations. The sidecar container operates as a plug-and-play solution, seamlessly intercepting, controlling, and transforming all HTTP1/HTTP2/gRPC traffic flowing in and out of DoorDash microservices — all without requiring any modifications to the application code.
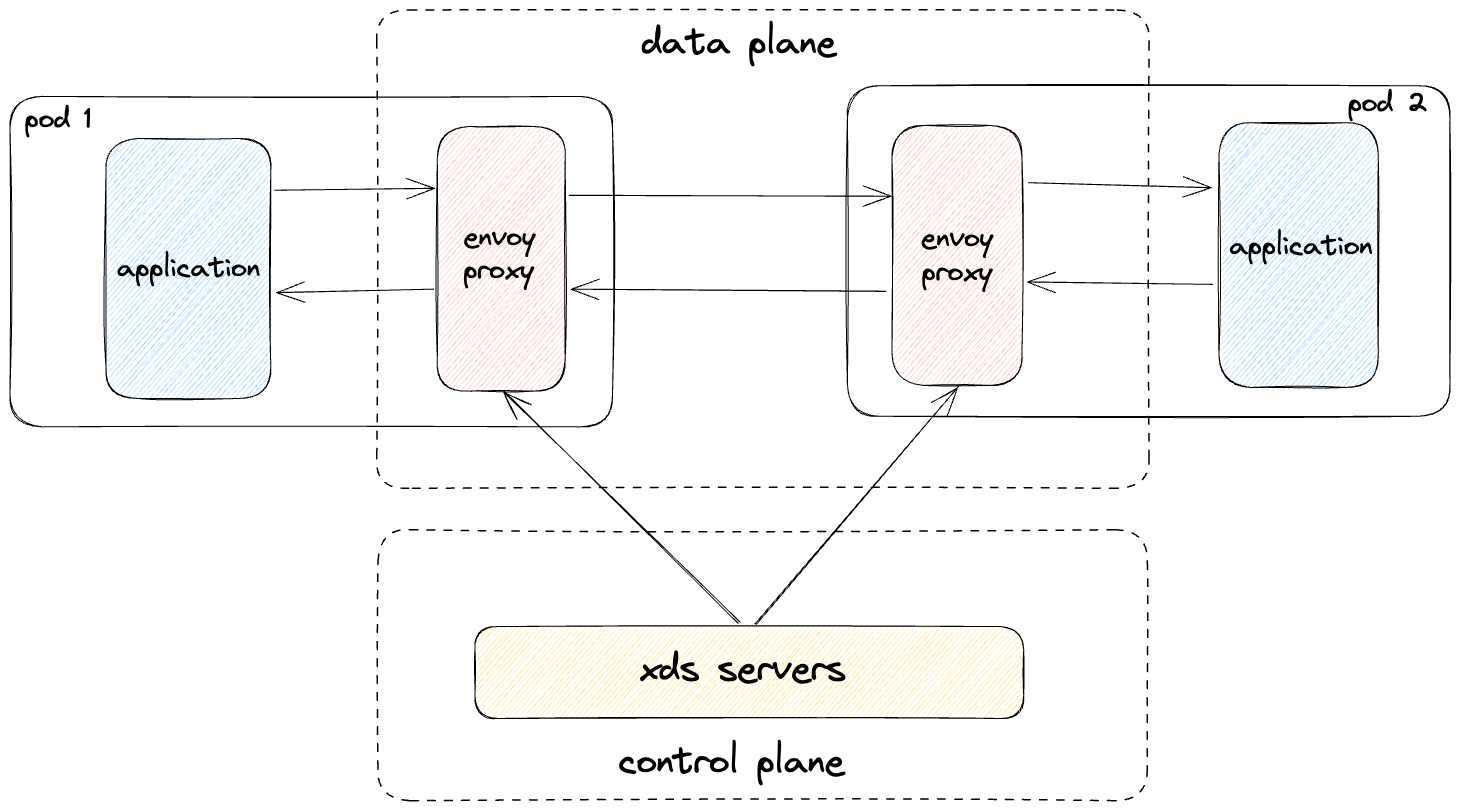
While DoorDash's traffic architecture has unique components, we believe the challenges and lessons we've encountered on our network traffic-related efficiency journey can be applied broadly to other architectures as well.
Common DoorDash data transfer patterns
For cross-AZ traffic, we categorize our traffic patterns as follows:
HTTP1/HTTP2/gRPC traffic: Direct pod-to-pod communication between microservices within the same cell; the traffic between microservices in the global cell and those in cells that involve an additional hop in the call path — such as internal routers — increases the likelihood of cross-AZ traffic.
Storage traffic: Includes traffic from microservices to stateful systems such as Aurora PostgreSQL, CockroachDB, Redis, and Kafka.
Internal infrastructure traffic: Internal Kubernetes traffic such as coredns traffic or communication between Kubernetes control plane components. This type of traffic usually uses Kubernetes internal DNS instead of DDSD.
Early hypothesis
We believed that HTTP1/HTTP2/gRPC traffic within the same cell was the largest source of cross-AZ data transfer costs because of our microservice architecture. We also determined that service mesh potentially could enable zone-aware routing for all microservices using that feature in Envoy. Understanding both of these things, we prioritized investigating and optimizing HTTP1/HTTP2/gRPC traffic patterns to improve efficiency without degrading service quality.
Addressing HTTP1/HTTP2/gRPC traffic costs
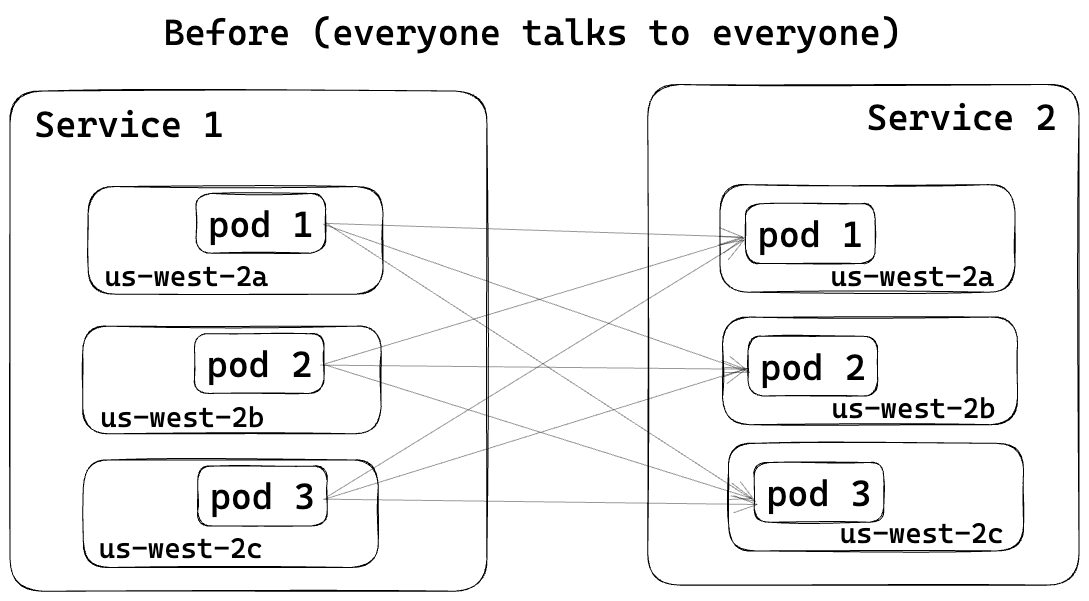
Originally, traffic between services was uniformly distributed across different AZs as shown in Figure 4. With Envoy’s zone-aware routing feature, caller services now prefer directing traffic to callee services in the same AZ, as shown in Figure 5, thereby reducing cross-AZ data transfer costs.
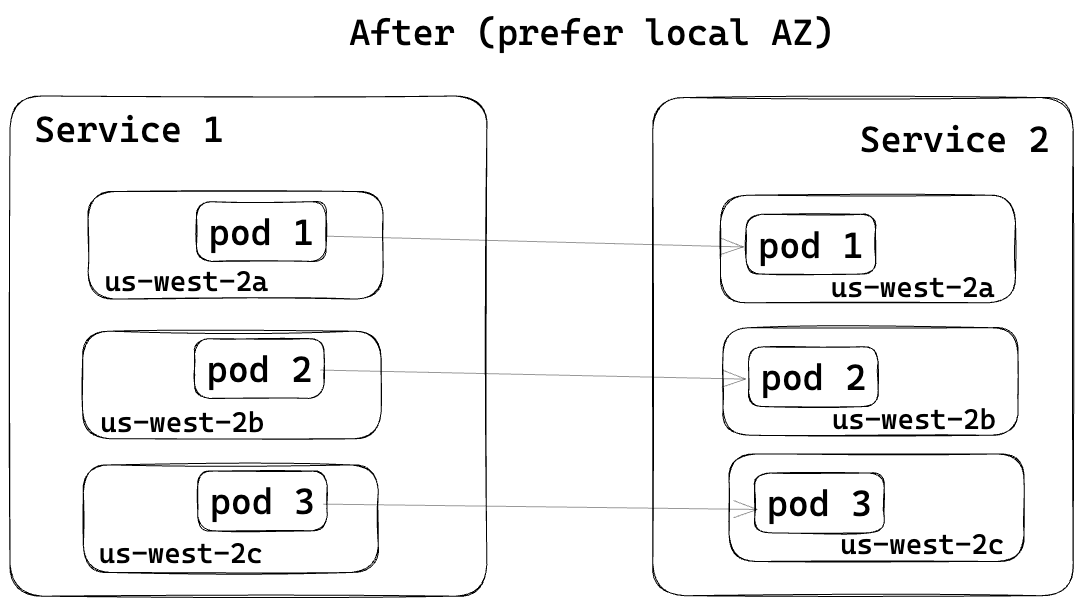
To enable Envoy’s zone-aware routing feature, we made changes in our control plane for service mesh, switching the service discovery type from STRICT_DNS to endpoint discovery service (EDS). As shown in Figure 6 below, for DDSD domains, the control plane now dynamically sends EDS resources from each Envoy cluster back to Envoy sidecar containers. The EDS resource includes pod IP addresses and their AZ information.
resources:
- "@type": type.googleapis.com/envoy.config.endpoint.v3.ClusterLoadAssignment
cluster_name: payment-service.service.prod.ddsd
endpoints:
- locality:
zone: us-west-2a
lb_endpoints:
- endpoint:
address:
socket_address:
address: 1.1.1.1
port_value: 80
- locality:
zone: us-west-2b
lb_endpoints:
- endpoint:
address:
socket_address:
address: 2.2.2.2
port_value: 80
- locality:
zone: us-west-2c
lb_endpoints:
- endpoint:
address:
socket_address:
address: 3.3.3.3
port_value: 80Figure 6: Example of one EDS response
With the data provided in EDS responses, Envoy retrieves the AZ distribution of both the caller service and the callee service. This information enables Envoy to calculate weights between pods. Although sending traffic via local AZs is still prioritized, some traffic may still be directed across AZs to ensure a balanced distribution and to avoid overloading any single pod as shown in Figure 7.
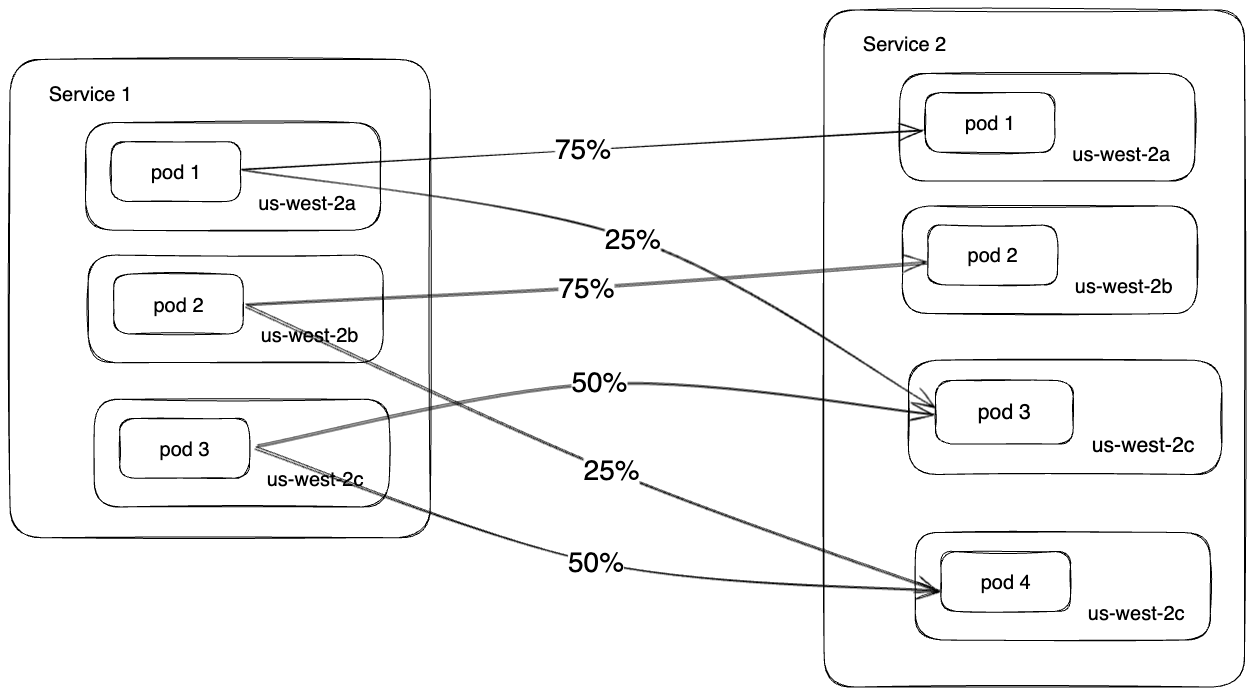
This routing solution offers several benefits, including:
- Maintaining traffic balance, even in scenarios where services are unevenly distributed across AZs
- Making it possible to dynamically set traffic weights between pods, eliminating manual operation
- Reducing the blast radius of a single or multi-AZ outage
- Reducing traffic latencies — caller services connect to callees that are more proximal
Our solution becomes even more effective when service pods are evenly deployed across AZs. To achieve this, we leveraged topologySpreadConstraints and set maxSkew to 1 with whenUnsatisfiable: ScheduleAnyway as shown in Figure 8. This means the Kubernetes scheduler will still schedule pods even without the condition being satisfied, prioritizing nodes that minimize the skew.
This approach ensures that pods are still scheduled; not doing so would reduce the amount of bin-packing, increasing idle compute and ultimately eating into zone-aware traffic-related cost reductions. In our production system, we observe 10% of traffic that is sent across AZs with this topologySpreadConstraints policy.
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnywayFigure 8: Configuration to deploy pods evenly across AZs
As we gradually rolled out the above changes, we saw improvements in our AWS cross-AZ transfer charges. Even so, we expected larger reductions. So, we set about investigating why we weren’t saving as much as we had anticipated.
Subscribe for weekly updates
Finding the needle in the haystack: Better visibility into cross-AZ traffic
We confirmed zone-aware routing was working as expected by validating Envoy metrics between AZs and logs from applications, but we needed more visibility into cross-AZ traffic to determine the root cause of the lower-than-expected reduction in data transfer costs. This led us to use a number of observability tools, including VPC flow logs, ebpf agent metrics, and Envoy networking bytes metrics to rectify the situation.
Using VPC flow logs, we mapped srcaddr and dstaddr IP addresses to corresponding subnets that were deployed in our AWS account structure. This mapping provided a roll-up rule that let us make sense of overall egress/ingress traffic patterns between different subnets hosting various parts of our cloud footprint, including subnets for production Kubernetes clusters, storage solutions, caches, and message brokers as shown in Table 1. We were able to confirm that our largest source of cross-AZ transfer costs is non-storage traffic within each cell. Around 20% of this cost was caused by traffic to one elastic load balancer (ELB) used for our event ingestion pipeline (Iguazu).

Additionally, we examined service mesh HTTP1/HTTP2/gRPC metrics, specifically connection bytes for all requests and responses for both ingress and egress traffic. The most important metrics from service mesh Envoy proxy are cx_rx_bytes_total and cx_tx_bytes_total from both Envoy listeners and clusters. However, because not all services were onboarded to service mesh at the time, we relied on metrics from BPFAgent, which is globally deployed on every production Kubernetes node, to increase visibility into total network bytes. Using metrics from both of these sources, we discovered that 90% of all traffic is HTTP1/HTTP2/gRPC traffic; 45% of that traffic had already been onboarded to service mesh and 91% of that portion of traffic is being sent to Iguazu!
Hops after hops: Iguazu’s traffic flow
After analyzing Iguazu’s traffic flow as shown in Figure 9, we realized there were several intermediary hops between the caller and callee services, or pods. When traffic moves from the caller services to Iguazu, it initially passes through ELBs, before landing on one of the worker nodes in a different Kubernetes cluster in the global cell. Because the externalTrafficPolicy is configured as a cluster, iptables redirects the traffic to another node to ensure load balancing.
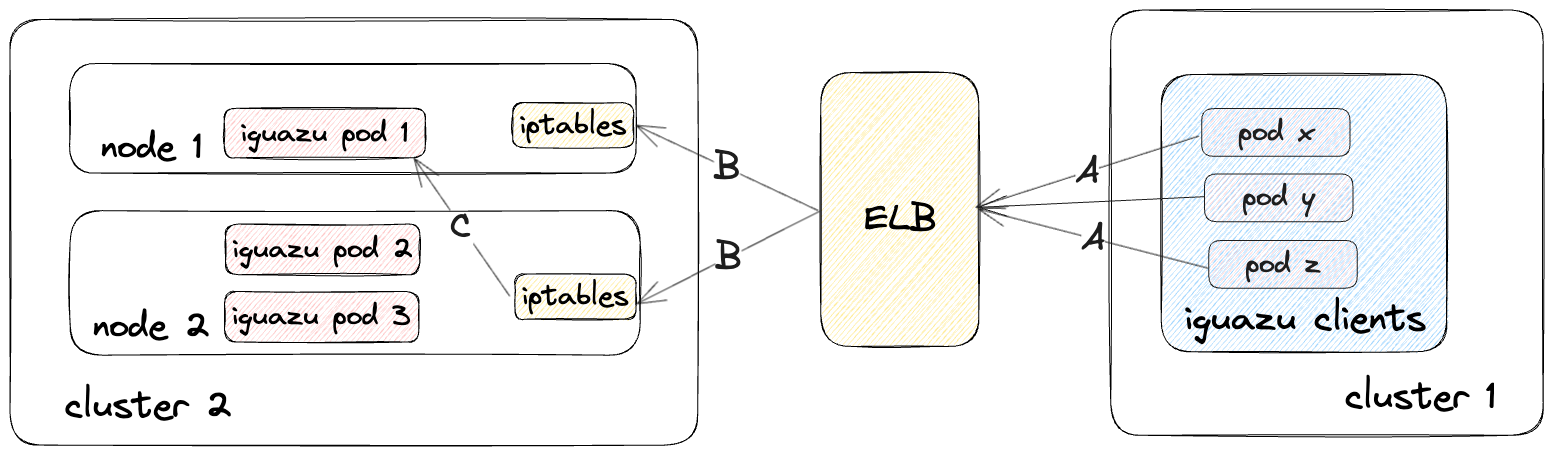
We observed the following data transfer behavior:
- Clients who were sending traffic to ELBs were still using the ELB DNS names directly. Because clients were not using the internal DDSD domains, the service discovery type in the Envoy cluster was still STRICT_DNS instead of EDS, which is a prerequisite for enabling zone-aware routing. This meant the Envoy sidecar containers used a simple round-robin approach to distribute traffic to the ELBs.
- Cross-AZ load balancing was disabled in the case of traffic from ELBs to Kubernetes worker nodes in Cluster 2.
- When traffic arrives at a Kubernetes worker node from the Iguazu ELB, it is subsequently redirected by iptables to a random node, which also increases the probability of cross-AZ traffic.
Given the complexity of multiple hops within the Iguazu call graph, we decided it would be best to migrate the Iguazu service to the same cell where their clients were deployed.
We also configured the routing rules of all clients’ Envoy sidecars to route traffic to Iguazu pods in the new cluster instead of talking to the ELBs — without requiring our engineers to make any code or config changes to their services. This allowed us to enable direct pod-to-pod communication for Iguazu traffic, enabling zone-aware routing while simultaneously reducing the volume of traffic processed by the ELBs as shown in Figure 10.
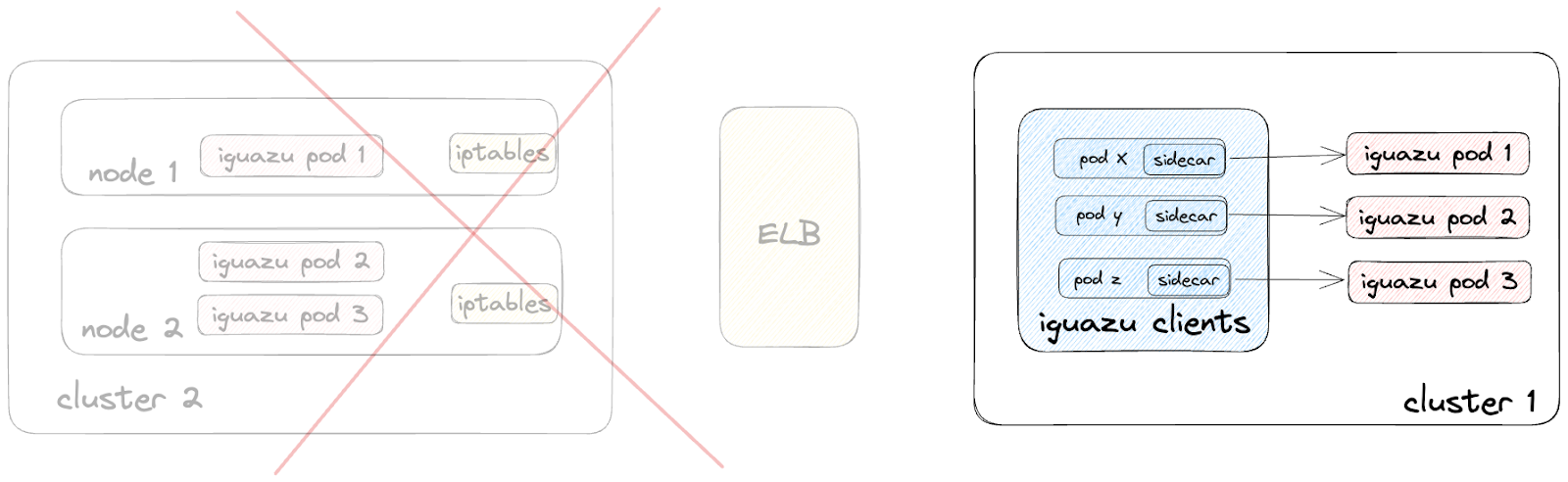
These actions made such a material dent in DoorDash’s data transfer costs as well as our ELB costs that it caused our cloud provider to reach out to us asking whether we were experiencing a production-related incident.
Lessons learned
Some of the key discoveries made during our journey include:
- Cloud service provider data transfer pricing is more complex than it initially seems. It’s worth the time investment to understand pricing models in order to build the correct efficiency solution.
- It’s challenging to build a comprehensive understanding/view of all cross-AZ traffic. Nonetheless, combining network bytes metrics from different sources can be enough to identify hotspots that, when addressed, can make a material dent in usage and cost.
- Envoy’s zone-aware routing can send traffic to its local availability zone while automatically ensuring resiliency through balanced traffic.
- As the number of hops increases in microservice call graphs, the likelihood of data being transmitted across AZs grows, increasing the complexity of ensuring that all hops support zone-aware routing.
- If you’re considering a service mesh for its traffic management features, you may also leverage it for greater efficiency.
- To learn more about DoorDash’s service mesh journey, check out Hochuen’s KubeCon + CloudNativeCon North America 2023 service mesh session.
Future work
We’ve already compiled a list of solution enhancements we’d like to implement, including:
- Streamline the process to gather metrics from different sources and provide a unified overview of cost and usage.
- Enable the zone-aware routing feature for internal Envoy routers
- Make the solution more extensible to support HTTP1/HTTP2/gRPC traffic using other domains beyond DDSD.
- Enable the topology-aware routing feature for internal infrastructure traffic using the Kubernetes network proxy kube-proxy.
- Explore optimized routing for large data transfer operations to or from DoorDash’s stateful systems, for example PostgreSQL, CRDB, Redis, and Kafka. This will allow traffic to remain in single AZ swim lanes whenever it makes sense, further reducing costs.
Acknowledgement
We thank Darshit Gavhane and Allison Cheng for migrating all Iguazu services to the same cell where clients are running, as well as Steve Hoffman and Sebastian Yates for their advice and guidance along the journey.








 JoshZhu
JoshZhu

 JobPortraits
JobPortraits

