

When moving from a monolith to a microservices architecture, engineering teams often need to master a new programming paradigm. During our own migration, we opted to base our new backend architecture on Kotlin, shifting away from Python. Kotlin coroutines were an area our engineering teams needed to quickly understand.
While Kotlin’s benefits include a rich ecosystem, interoperability with Java, and developer friendliness, many engineers are unfamiliar with using Kotlin in backend development. It's typically considered a frontend language, but it also allows implementing robust and high performance backend services.
We created this guide to help engineers understand how coroutines work in Kotlin, as compared to Java threading. We will discuss what coroutines are, get an overview of language, library and scheduling components of Kotlin coroutines, and then deep dive into these components. The guide also helps illustrate programming with coroutines in general.
What are coroutines?
Let’s start with the basics. Coroutines, according to Wikipedia, are “computer program components that generalize subroutines for non-preemptive multitasking, by allowing execution to be suspended and resumed.“ Kotlin’s native language and runtime support for coroutines allows easy asynchronous programming when building high performance applications. Compared to a Java thread, a Kotlin coroutine has a smaller memory footprint and lower overhead in context-switching.
The example below comes from Kotlin’s official tutorial. This example created 100K coroutines with a few lines of code. The highlighted code will be executed in coroutines. Each coroutine prints a dot character after five seconds. The language and standard libraries make it super convenient to create coroutines, and the Kotlin runtime scheduling hides the complexities of managing concurrent coroutines.
import kotlinx.coroutines.*
//sampleStart
fun main() = runBlocking {
repeat(100_000) { // launch a lot of coroutines
launch {
delay(5000L)
print(".")
}
}
}
//sampleEnd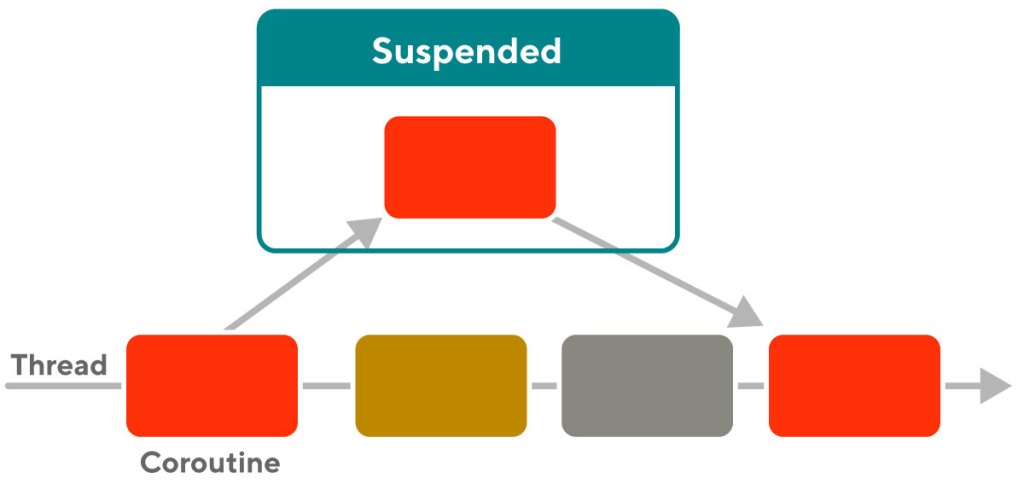
Figure 1 above shows how a coroutine’s body (actual code written by a developer to achieve a certain purpose) is executed by a thread. Coroutines are also suspendable. meaning that when a coroutine is waiting for an external response (such as a network response or a device I/O) it becomes suspended and the Kotlin scheduler moves this coroutine off the thread. The same thread can then pick up other coroutines waiting to be executed. This way coroutines appear to always be executing concurrently (but may not be simultaneously). In fact, replacing “suspended” with “blocked” and “coroutine” with “thread” points to an obvious analogy in that coroutines and threads both enter waiting states and can resume executing after transitioning out of waiting states.
In addition to the code blocks in the above example, a function can be defined as suspendable using the keyword, “suspend”:
suspend fun doSomethingUsefulOne(): Int {
delay(1000L) // pretend we are doing something useful here
return 13
} In the above example, a coroutine running doSomethingUsefulOne will suspend upon executing the delay call, which makes the coroutine wait for one second. When the delay is finished, the Kotlin scheduler puts the suspended coroutine back into the thread for execution, returns 13 and finishes this function call.
By design, it is convenient to write asynchronous programming code without nested callbacks. Asynchronous calls, such as the delay code above, simply become suspend points and developers can focus on business logic.
Overview of the language, library, and scheduling components
Approximately three components, the Kotlin language, the standard library, and scheduling, combine to make coroutines work in Kotlin.
- Language: The Kotlin language compiles directly to JVM bytecode. The runtime context and control flow states of a coroutine are managed through a mechanism called continuation passing. First, a method is called, and local variables are created on the stack. Then, upon suspension, the runtime saves all the local variables used so far, saves where the code has executed so far in this method, and returns the state. Finally, upon resume, the runtime restores all the local variables from the saved context, jumps to where the code was suspended, and resumes execution.
- Standard library: All the support for coroutines is written in Kotlin’s core libraries. A coroutine internally uses a Continuation class to capture the contexts for its execution. Then the dynamic aspect is modeled as a Job class. The use of async usually creates a Deferred job, which is a subclass of the Job class. The CoroutineContext type is required for a coroutine to execute. To summarize:
- “Continuation” is concerned with how Kotlin passes around blocks of code in a higher order functional way.
- “Job” is concerned with how Kotlin manages the lifecycle of a coroutine (cancelled, completed, active, etc.).
- “CoroutineContext” is concerned with the runtime of a coroutine or a group of coroutines, such as how it’s dispatched or existing context data. One of the important related concepts is CoroutineScope which defines an interface to wrap the coroutine context and facilitates context propagation among coroutines.
- Scheduling: This is actually also part of the standard library. With language support we have a coroutine natively represented as some mechanisms in JVM bytecode. With standard libraries we are able to write code to create coroutines. The last step is to make the JVM runtime execute coroutines.
- There are many ways to schedule a coroutine. Some common ways include default scheduling, which uses the CoroutineScheduler, and ExecutorCoroutineDispatcher, which wraps around a Java SDK Executor thread pool.
- When a Job is ready to execute, it will be executed as a DispatchedTask. The code block (coroutine in byte code) will be run and the returned state will further be dispatched through a dispatcher.
A closer look at the Kotlin language for coroutines through compiled codes
Let’s see in a code sample what a coroutine is. We will use a suspend function, shown in Figure 2, below, as the running example. In this example we used the IntelliJ IDE for Kotlin-to-bytecode inspection and JVM bytecode decompilation.
The IntelliJ IDE supports inspecting a Kotlin function through compiled JVM bytecodes. This means we can compare side by side a snippet of Kotlin code and the corresponding JVM bytecodes the same Kotlin code compiles to. This feature is located in the “Tools” option in the IntelliJ IDE. By opening the Tools option list we can further locate the “Kotlin” option to see the “Show Kotlin Bytecode” option.
The figure below is an example that shows what we would expect to see the side by side comparison between a suspend function in Kotlin and its corresponding bytecodes on the right.
After seeing the JVM bytecodes of a Kotlin function we can rely on IntelliJ to de-compile the bytecodes back to Java. With the bytecodes in the above example (Figure 2, right hand side), the de-compiled Java code looks like below (figure 3):

Ignore the details of variable names (they are programmatic and hard to read, because they were generated in a programmatic way), and for now let’s focus on the following aspects of the aforementioned code snippet:
- The code uses labels: Java supports goto statements through the use of labels. We will soon see that scopes and labels are used extensively as the way to implement coroutines. Now we know a Kotlin suspend function (the static aspect of a coroutine) will be compiled into a static JVM method.
- One label is defined as an int variable: Using an int variable label is very important because it serves as the key to a switch statement for a coroutine to resume back to where it left off.

From the above example we are making several observations regarding how the code is written and structured:
- The smallest execution unit is the code between two suspend calls within a method. If we have a method where we call 50 suspend functions, logically Kotlin considers this method to have up to 50 units of execution scheduling (as the upper bound).
- Case 0 is special. It corresponds to the beginning of a method up to the first call site of a suspend function. This implementation detail perfectly explains the documentation on the Kotlin website: “... The Dispatchers.Unconfined coroutine dispatcher starts a coroutine in the caller thread, but only until the first suspension point…”
- Notice this variable: Object var8 = IntrinsicsKt.getCOROUTINE_SUSPENDED(). We can see that a suspend function can either return IntrinsicsKt.getCOROUTINE_SUSPENDED() or the actual result of the function. If the return value is the former case, we know the suspend function we are calling is not ready, and we need to suspend the current function and return.
- Notice the variables: L$0, L$1, L$2…. These are the states to save for local variables. When the coroutine resumes, these variables will be restored with the saved values. Also, Kotlin captures all necessary local variables statically at compile time and makes them member objects of the continuation class.
Now let’s see another more complex example:

Notice the break labelxx statements and similar try blocks. The innermost scope has a switch statement, which is the control flow statement we discussed before as the jump table for suspend code blocks. The Kotlin compiler programmatically generates numbered label scopes for suspend code blocks. In the above example, if label == 1, it breaks off to run the try block immediately following the switch block. If label == 2, it breaks off to run the try block immediately following label477’s block, and so on.
Now we can see that with the control flow switch statement, local variable capturing, and labeled code scopes, Kotlin has implemented the control and data flows of a coroutine in JVM.
Before concluding this section, let’s examine the following code snippet:


This file in Kotlin’s compiler generates the above bytecode:

Introducing Kotlin’s standard library
Kotlin provides a set of out-of-the-box classes and utilities to make app development easier. Kotlin’s classes and utilities are wrapped inside the Kotlin standard library. In this section we will examine a few classes to illustrate how they facilitate development with coroutines.
We will use the following code (which is a Kotlin async code block) to see what we could find out:

Then it leads us to the Builders.common.kt file.

There are a whole bunch of classes that we don’t know about yet in the above figures. Let’s do some more digging to understand the functionalities of each class in the above example:
- CoroutineContext: We see this almost everywhere throughout the code bases. It’s used for passing some context and data as key-value pairs. What’s interesting is the
public operator fun plus(context: CoroutineContext): CoroutineContext method. Now we know why we sometimes do “context + something” when we launch new coroutines. The “+” is just an “operator overloading” defined for CoroutineContext. - CoroutineStart: This determines how and when a coroutine should start. Ignore other cases (we only occasionally or rarely do), and focus on DEFAULT. Later the file defined the “invoke” operator overloading. In Java/JVM “invoke” means “calling”. This means CoroutineStart essentially is a “Functional Interface”. It in turn will call
startCoroutineCancellableof the provided block, which is of type suspend () -> T. Recall the Language section where we use the same trick to see what Kotlin does with it. Below is the result:
/** A function that takes 1 argument. */
public interface Function1<in P1, out R> : Function<R> {
/** Invokes the function with the specified argument. */
public operator fun invoke(p1: P1): R
}
It’s a functional interface with one input parameter. Of course, every suspend function under the cover will have one extra parameter, which is the Continuation object.
- Deferred: From tracing the source code we know it’s a subclass of Job. And this “Deferred” class has a result. From this observation we now know that an “async” call does a bunch of bookkeeping and finally creates a coroutine and dispatches a Deferred Job with a result.
- Job: This file is rather big and complicated, but it’s well documented. It defines the state machine of a job. The description of this state machine is “... A background job. Conceptually, a job is a cancellable thing with a life-cycle that culminates in its completion.” A few things worth noticing:
- A job only completes when all children jobs are completed.
- A child job’s cancelation will cancel the parent job.
- Cancellation is such an important concept that Kotlin models it natively and weaves this concept throughout its implementation for coroutines.
We have looked at a bunch of Kotlin classes for async and coroutines. Here are a few takeaways:
- Whenever in doubt, we could just look at the implementation given that the core classes are not too many and it’s fairly straightforward to understand what Kotlin does under the covers.
- Coroutines have their code represented as static Java method/classes in bytecode in compilation time. Coroutines have their runtime data structures represented as Jobs along with contexts, which are just a bunch of JVM objects which are object oriented pointers. Coroutines are indeed cheap (compared to creating tons of threads which in turn create the same number of Linux threads).
- Coroutines, at the end of the day, are just a bunch of jobs getting scheduled and executed at some point in JVM. As long as we keep that in mind, from a programming model perspective it’s very similar to thread programming.
Scheduling coroutines
So far we figured out how JVM understands a coroutine so it can run a coroutine, suspend a coroutine, and resume a coroutine. We also figured out how a coroutine is represented with core classes in the Kotlin standard library. Now let’s look at how a coroutine (or a Job) is actually getting run in JVM.
There are quite a number of ways to run coroutines. The official documentation has a good high-level overview. We will take an implementation perspective. Here we examine three types (in fact there could be more, but this article is not intended to be exhaustive):
- Event loop-based: A thread runs a while true loop looks for jobs to execute in its queue. Such an event loop also takes care of scheduling delayed jobs (e.g. scheduling to run in the future given a delay time). Usually when we do runBlocking or launch(Dispatchers.Unconfined) we end up submitting a coroutine to an event-based dispatch for execution.
- CoroutineScheduler: This work stealing scheduler is used as the default dispatcher. The dispatcher spawns a pool of worker threads with each thread attached to a designated CPU core. Each worker maintains a local job queue and in addition there is a global queue. Jobs (coroutines) submitted by a worker will be added to the worker’s local queue. And workers can steal other workers' jobs in their local queues to work on so that, on average, if there are P processors and N jobs the workload per processor is expected to be N/P. Golang’s scheduler is similar to this design, which is commonly referred to as m:n scheduling.
- ExecutorCoroutineDispatcher: This is the most used thread type throughout DoorDash’s codebases. Essentially it wraps around a plain Java Executor. Each submitted coroutine is also wrapped as a Runnable, a type expected by the Java Development Kit. The per-thread affinity is not preserved, because when a coroutine returns due to suspension, the next scheduling will be added to the thread pool’s job queue. And every thread has a fair chance to grab it (most common thread pool implementations).
Whenever a coroutine is up for execution by one of the dispatcher types, the following code will be run (in normal use cases):
- A DispatchedTask will be used to represent a coroutine job in the context of a Dispatcher. This is a subclass of kotlinx.coroutines.scheduling.Task, which in turn is a subclass of Java’s Runnable.
- The DispatchedTask’s overriding run() method does all the magic for running a coroutine, including:
- Bookkeeping to prepare for coroutine state to pass into the continuation
- Running the coroutine code block (recall from the Language section how that’s done) with the states and contexts to pass to the code block
- Checking return results. And, if there is more work, dispatch (e.g. submit to the worker queue) again the next call for the coroutine with the newly obtained context from the return result. This way at some point in the future the dispatcher’s thread(s) will pick up the new work from the queue and run it.
Before concluding this section, a few points about scheduling:
- Event loop-based dispatchers will be frequently referred to in the mobile app development (e.g. main thread). We need to be careful not to schedule anything CPU-intensive (or blocking the event loop thread).
- The default dispatcher is a general purpose dispatcher which is optimized for CPU-intensive computation with no-blocking. The reason is that default dispatch only has a small set of worker threads (number of cores) blocking any of these would significantly hurt the throughput.
- Executor dispatchers are more tolerant to misuses. But in that case the general wisdom of Java concurrently/threading/performance will apply. Properly sizing the thread pool is always a good approach toward more predictable Kotlin service performances.
Conclusion
We have examined Kotlin coroutines from multiple angles through a combination of source code reading and bytecode/Kotlin compilation/decompilation exercises. Now we know that coroutines are resumable tasks that are lightweight to create and schedule. We also know when and how a coroutine suspends during its execution. Finally we have a better understanding of what mechanism is used for scheduling the execution of coroutines. These deeper understandings of coroutines should guide us writing high performance code, or simply, better code in Kotlin.








 PatrickRogers
PatrickRogers




Great article.
Thank you for sharing this.
Really helpful article thanks for sharing
Thanks for the article, it’s really helpful.
We’ve been using Kotlin for some of our services at Netflix for a while as well, and I generally really like it, but troubleshooting coroutine scheduling has been a pain point as most of the observability tooling is not ready to understand them.
You mentioned you’ve been mostly using a thread pool executor-based scheduler for your backend services. I’d be super interested in learning more about your setup, as I’ve experimented with replacing the default scheduler with an executor and my initial results were not great. Any details you could share would be awesome!
@Luis good question! Right now as mentioned we are wrapping threadpools with https://github.com/Kotlin/kotlinx.coroutines/blob/81e17dd37003a7105e542eb725f51ee0dc353354/kotlinx-coroutines-core/jvm/src/Executors.kt
Then internally we built another layer of DAG execution scheduling on top to allow higher level scheduling for DAG executions.
Would it be possible for you to give an example of how you use ExecutorCoroutineDispatcher at DoorDash?